
花指令
花指令
什么是花指令
花指令实质就是一串垃圾指令,它与程序本身的功能无关,并不影响程序本身的逻辑。在软件保护中,花指令被作为一种手段来增加静态分析的难度,使程序无法很好的反编译。花指令也可以被用在病毒或木马上,通过加入花指令改变程序的特征码,躲避杀软的扫描,从而达到免杀的目的。
花指令大致可以分为可执行花指令和不可执行花指令。
这两天我学习了两位大佬的博客,想着写一个花指令并且带有对应练习题目的总结。
https://blog.csdn.net/Captain_RB/article/details/123858864
https://bbs.kanxue.com/thread-279604.htm
学习花指令的准备
在一个程序中想要理解发现花指令就必须要理解明白汇编指令。
push ebp —-把基址指针寄存器压入堆栈
pop ebp —-把基址指针寄存器弹出堆栈
push eax —-把数据寄存器压入堆栈
pop eax —-把数据寄存器弹出堆栈
nop —–不执行
add esp,1—–指针寄存器加1
sub esp,-1—–指针寄存器加1
add esp,-1——–指针寄存器减1
sub esp,1—–指针寄存器减1
inc ecx —–计数器加1
dec ecx —–计数器减1
sub esp,1 —-指针寄存器-1
sub esp,-1—-指针寄存器加1
jmp 入口地址—-跳到程序入口地址
push 入口地址—把入口地址压入堆栈
retn —— 反回到入口地址,效果与jmp 入口地址一样
mov eax,入口地址 ——把入口地址转送到数据寄存器中.
jmp eax —– 跳到程序入口地址
jb 入口地址
jnb 入口地址 ——效果和jmp 入口地址一样,直接跳到程序入口地址
xor eax,eax 寄存器EAX清0
CALL 空白命令的地址 无效call
常见的机器码
| 机器码 | 指令 | 格式 | 说明 |
|---|---|---|---|
| 0xE8 | CALL | E8 xx xx xx xx | CALL 指令后面跟的是一个4字节的相对偏移地址(相对于下一条指令的地址) |
| 0xE9 | JMP | E9 xx xx xx xx | JMP 指令后面跟的是一个4字节的相对偏移地址 |
| 0xEB | JMP | EB xx | JMP 指令后面跟的是一个1字节的相对偏移地址 |
| 0xFF 15 | CALL dword ptr [addr] | FF 15 xx xx xx xx | 从指定地址中读取一个地址,然后 CALL 那个地址 |
| FF 25 | JMP dword ptr [addr] | FF 25 xx xx xx xx | 从指定地址中读取一个地址,然后 JMP 到那个地址 |
不可执行花指令
花指令虽然被插入到了正常代码的中间,但是并不意味着它一定会得到执行。这是利用反汇编器的静态分析算法的缺陷使得代码在插入的花指令处反编译出错。
反汇编器的静态分析算法分为两种:
1.线性扫描:从程序入口处依次读取机器码并进行反汇编,逐行命令进行线性扫描,在于在冯诺依曼体系结构下,无法区分数据与代码,从而导致将代码段中嵌入的数据误解释为指令的操作码,采用线性扫描技术的反汇编工具如OD、Windbg;
2.递归下降:从程序入口开始读取机器码进行反汇编,通过程序的控制流确定反汇编的下一条指令,遇到无条件跳转则从跳转目的地址处继续解析,遇到条件跳转则从两个命令执行分支处进行解析 (优先解析顺序执行分支),即采用模拟程序运行的方式增加反汇编的准确度,采用递归下降反汇编的如IDA。
在设计这类花指令时要通过构造 必然条件 或者 互补条件,使得程序在实际执行时绕过垃圾数据,这样不会影响程序正常执行。
形式一:简单跳转
如果插入的花指令是一个操作码,比如0x33(xor指令的操作码),0xE8(CALL指令操作码)等,那么后面程序原本的机器码就会被认为是这个操作码的操作数,从而导致反汇编引擎的解析错误。
例题1:NSSCTF-[GFCTF 2021]wordy
用IDA打开这个题目,发现找不到main函数,那很大概率就是因为花指令插在了main函数里面,导致其没有办法被IDA反汇编出来。我们可以使用IDA文本搜索的功能,搜索main。这就能找到main函数。
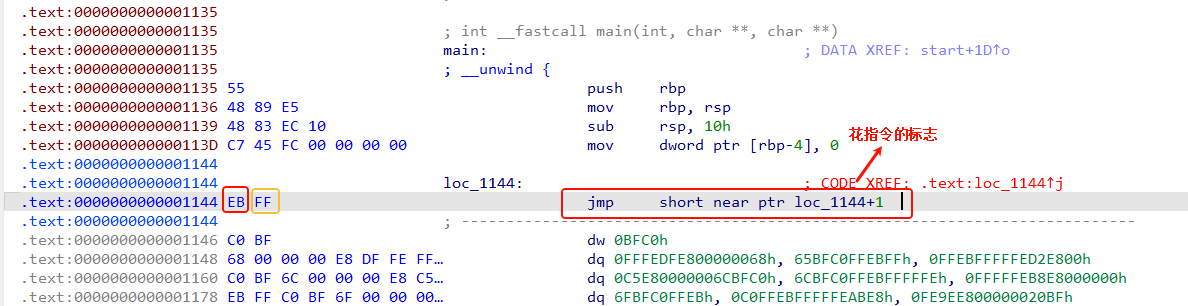
我们可以知道起始地址是0x1135,发现jmp指令短跳转的地址还加上了1,说明是从FF开始的,把EB跳过去了。在这里EB其实就是一个垃圾字节,并没有什么用,但是因为0xEB是指令JMP的机器码,所以这个花指令插在这里就被错误的识别了,导致解析错误,形成了一个跳转指令。我们可以按U将这个指令解除定义,然后把 EB nop掉,再将下面的按P重新定义一下就好了。

但是我们发现了这个程序被插入了很多很多的0xEB这个花指令,其原理都是一样的,手动nop实在太吃时间和精力了,我们就可以上脚本。
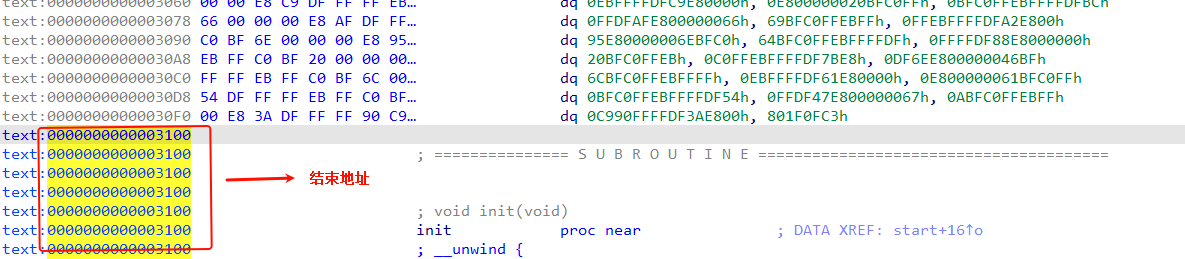
找到结束地址:0x3100
在IDA-File-Script Command 里应用下面的脚本,要注意的是下面的语言要改成python
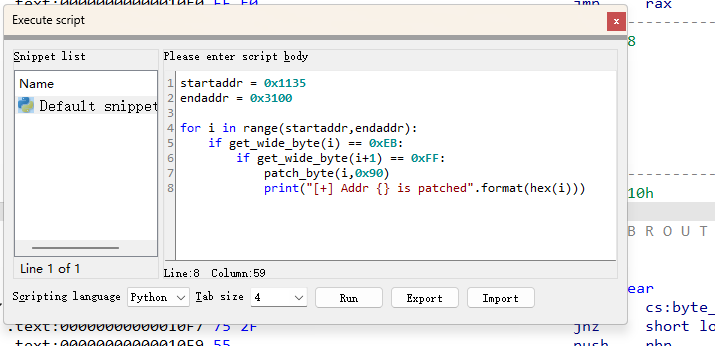
1 | startaddr = 0x1135 |
解释一下:就是在指定要扫描的内存地址范围 [0x1135, 0x3100]中遍历每一个地址 i ,如果地址 i 的字节是0xEB,并且它的下一个字节是0xFF,就将这个地址 i 变成0x90给nop掉,最后输出补丁信息,提示某个地址处的 EB 被nop了。

完成后就可以看到flag了,也可以在main的函数头U解构一下,再P重构一下,F5就能将它反编译了,也可以在反编译后的伪C代码里面找到flag。
例题2:NSSCTF-jump_by_jump
这个题目就是上述中设计这类花指令时要通过构造互补条件来执行的
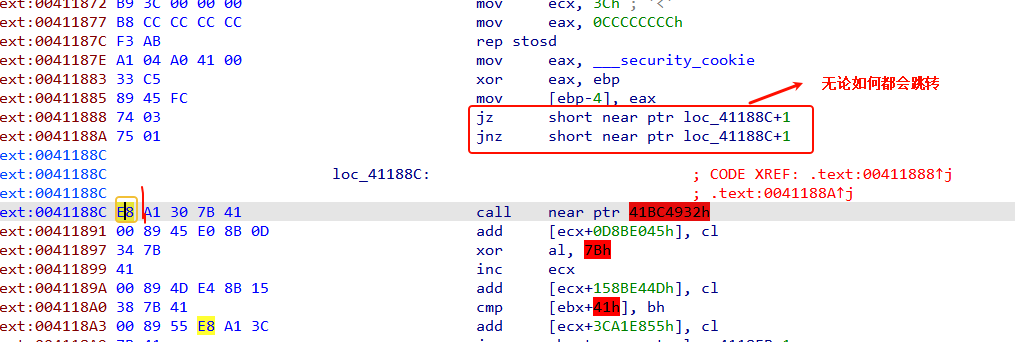
看到 jz 和 jnz 都跳转到同一个地址,这就是互补条件来使程序绕过垃圾数据,与上一题的处理方法相同,E8就是垃圾字节,程序会跳过它,但是会错误的识别这个机器码为call。将loc_41188C处按U解除定义,然后将0xE8 nop 掉,剩下的按C转为代码。
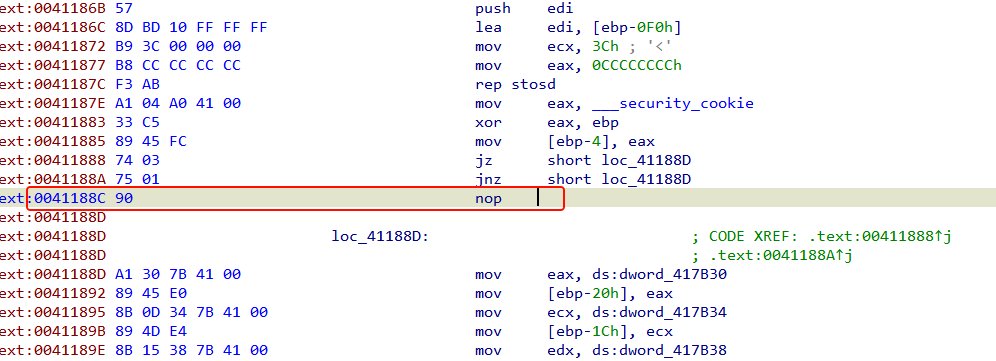
再在main函数头按U解构一下函数,再按P重构这个main函数,就能F5反编译了
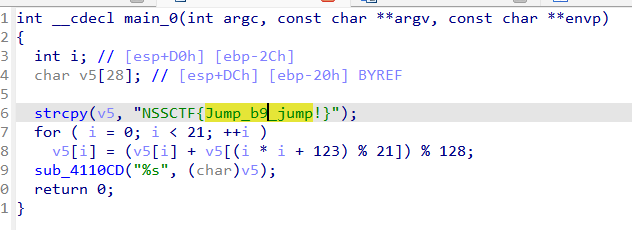
形式二:破坏堆栈平衡
汇编中函数如果有参数或局部变量,在调用前会对堆栈进行保护 ,在返回前要还原函数调用前的堆栈,这一过程程序在编译时会自动加上,如果反编译器检测到指令破坏了堆栈平衡,即函数返回时与调用时堆栈状态发生了变化,就会报错。可以利用这一点构造破坏堆栈平衡的花指令。
堆栈不平衡指的是函数调用或返回过程中,esp(栈顶指针)的值不匹配了
下面举出一个例子:
花指令可以使用VS2022 x86架构 C++ 来编译 这个带有内联汇编的代码。
1 |
|
分析一下原码:由于xor eax,eax 是 eax = 0;jz s 这个跳转就一定会执行,从而它的下一步 add esp,0x11 就不会被执行,这个就是破坏堆栈平衡的花指令,但并不会影响程序的运行。只是在IDA进行进行静态分析时,会假设可能会执行的情况来分析所有路径,所以会导致程序堆栈不平衡。
编译一下后用IDA打开
然后 Options-General勾选上显示栈指针,填上显示的字节码 8后,再进行分析
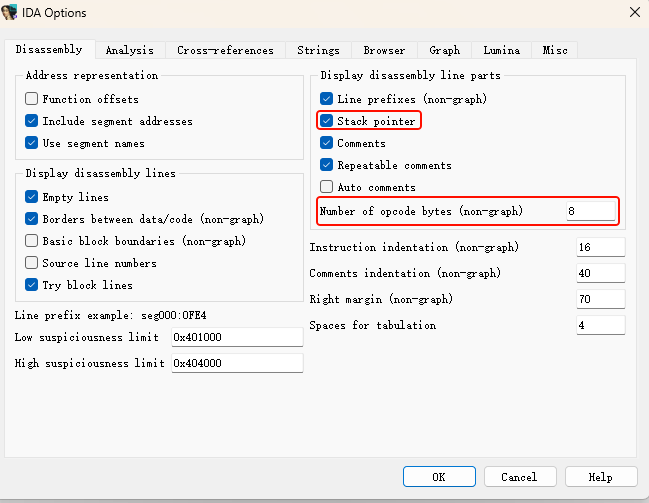
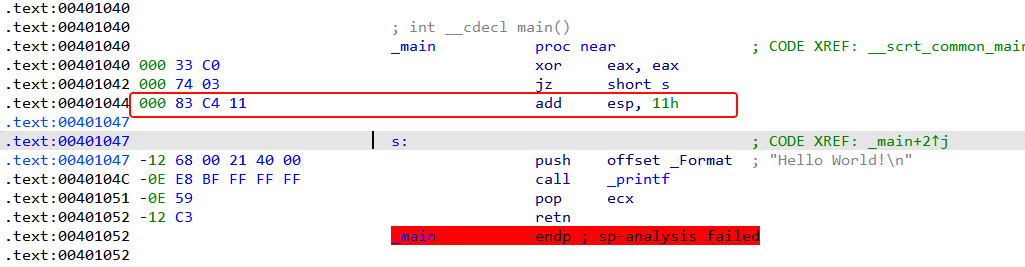
这个指令就是花指令,并没有被执行但却影响了IDA整体的分析,直接nop掉就行了
然后再在main函数头先U解除定义一下,再P重新定义一下就好了

可执行花指令
花指令在程序执行过程中会被执行,但执行这些代码没有任何意义,执行前后不改变任何寄存器的值,也不改变程序执行逻辑和结果,目的是加大静态分析的难度,或是混淆特征码,绕过特征检测。
形式一:call+ret
call 指令:将下一条指令的地址压入栈作为返回地址,然后跳转到函数地址,相当于push 下一条指令地址,mov eip,函数位置
ret指令:从栈顶弹出返回地址,相当于pop eip
push 入栈,pop 出栈,这些操作指令进行组合使用,就能使返回地址跳到任意地方,从而构造花指令
例题1:NSS-[HNCTF 2022 WEEK4]flower plus
使用IDA打开,看到main函数,但是无法进行反编译,就知道main函数里插花了。来回看看,发现main函数上面也被插花了,两种花,还挺多。那我们就要考虑上脚本了。
第一种花
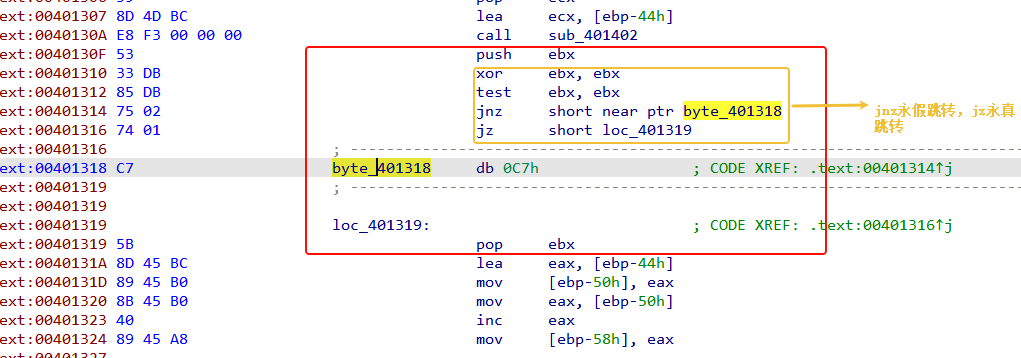
在黄色框中,xor ebx, ebx 使ebp=0,test ebx, ebx 使ZF标志寄存器值为1,那么就只会进行jz跳转,而不进行jnz跳转。
那么0xC7就会被跳过,它就是插入的花指令。但是我们nop的话可以将红色框住的全部都 nop掉,也就是从push ebx,到pop ebx。
因为,push ebx:将寄存器 ebx 当前的值压入栈顶。pop ebx:从栈顶弹出一个值,恢复到 ebx。当中间不修改 esp 且不使用栈值时,这两条指令连用会恢复原状,相当于什么都没做,它们对程序逻辑无影响,属于冗余代码。所以都nop了。
第二种花:call指令
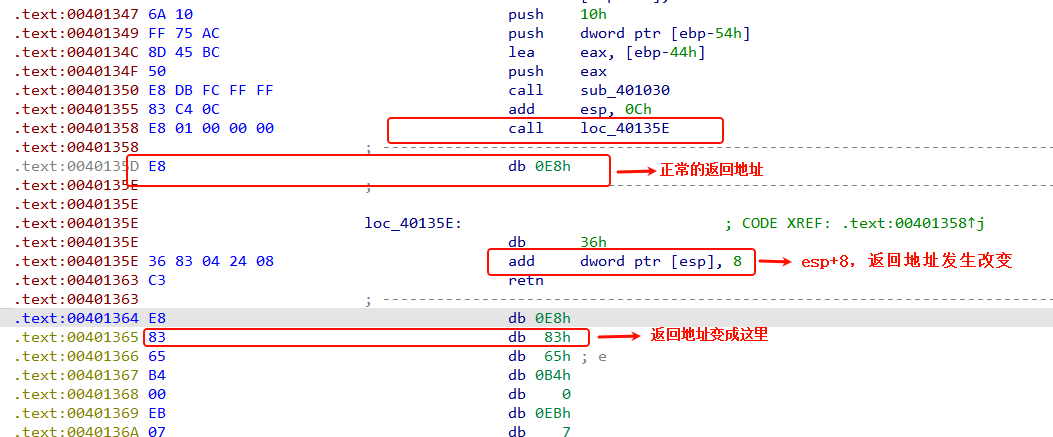
call loc_40135E 它会把 0x0040135D(下一条指令地址)压入栈中作为返回地址,并且正常调用 loc_40135E。
在loc_40135E 开始执行时,0x36是一个无意义的字节,然后执行add [esp+68h+var_68], 8
esp指的是栈顶的内存地址,当前栈顶存放的内存地址是0x0040135D,这条指令的作用是,将栈顶存放的那个 dword 值(即 0x40135D)加上 8,然后把结果再写回栈顶。所以新的返回地址就变成了0x40135D + 8 = 0x401365。
那就说明,这个call相当于跳转到了0x401365执行,从call 指令到新的返回地址之间的指令都没有用了,这部分是花指令,可以直接nop掉。
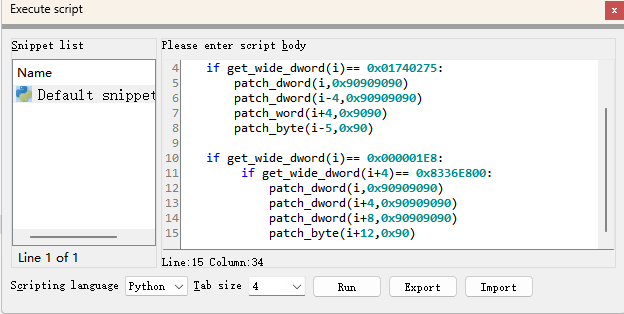
这个程序里面有很多一样的这两种花指令,我们通过脚本来进行修改
找到起始地址 0x00401006 和结束地址 0x00401402,

1 | startaddr=0x00401006 |
解释一下:
第一个花指令:0x01740275 是反汇编形式的字节序:75 02 74 01(jnz + jz),patch_word(i-5, 0x90)是把push ebx替换为NOP
patch_dword(i-4)是将xor ebx, ebx 和 test ebx, ebx都nop,patch_word(i+4,0x9090)是继续nop掉 jnz + jz后面的pop ebx。
第二个花指令:0x000001E8是 call指令,如果他的后面是0x8336E800,也就是有add这个操作指令,就找对了,然后进行nop。结合上面的图来看,这就是将这个call指令到0x83上面的0xE8都nop完。
patch_dword 会改 4 字节(可能覆盖其他合法代码);
patch_word 改 2 字节;
patch_byte改1字节;(如果只是想把某个跳转指令的最后一个字节变成 NOP,那就只能打 1 个字节时可以用)
然后我们找到函数头和尾U解构一下,再P重构一下,就能F5反编译了
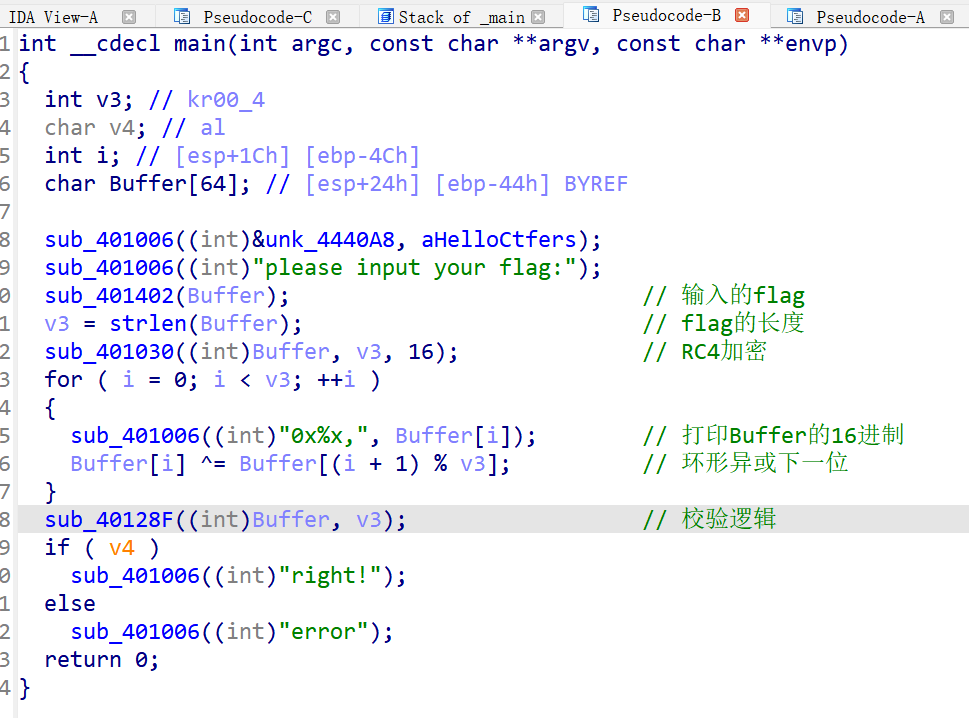
到这里花指令已经去除了,下面就是要分析加密方式来得到flag
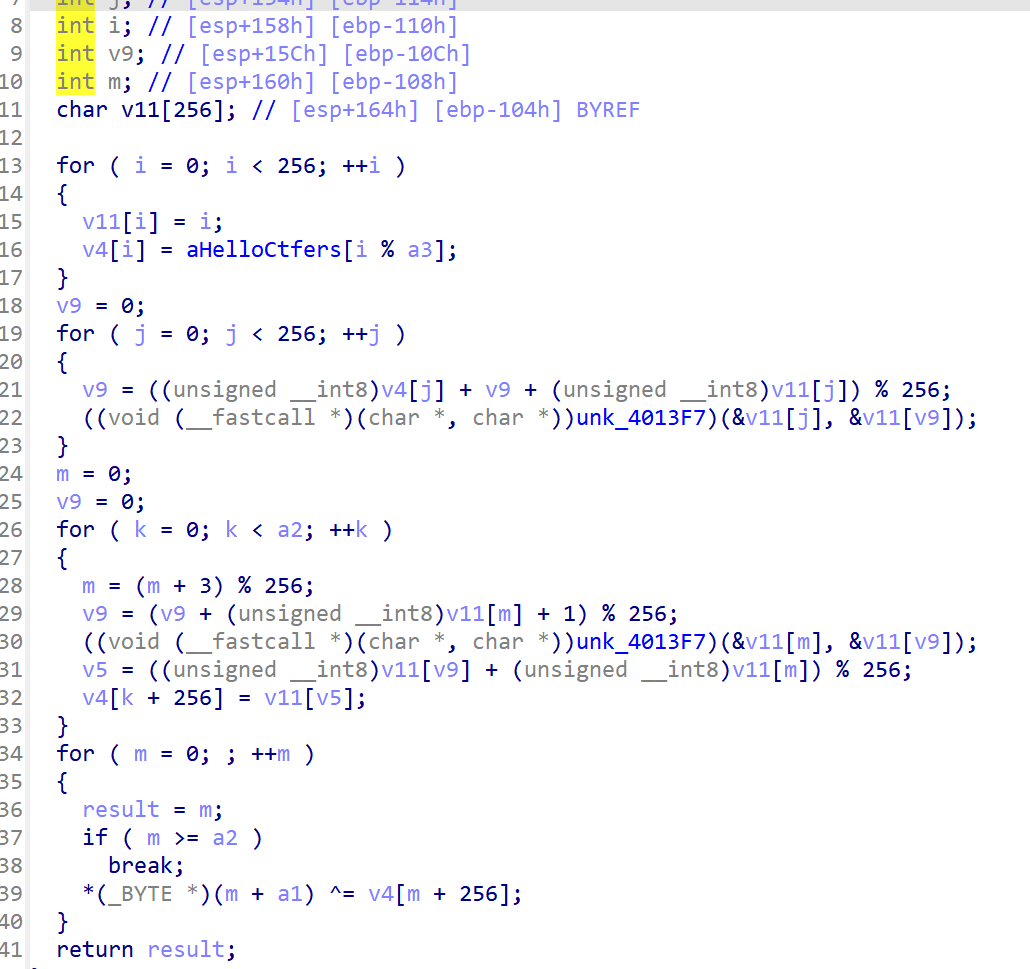
这是RC4的变种
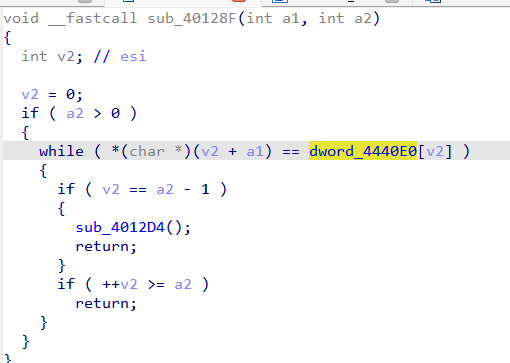
这个就是具体的校验逻辑
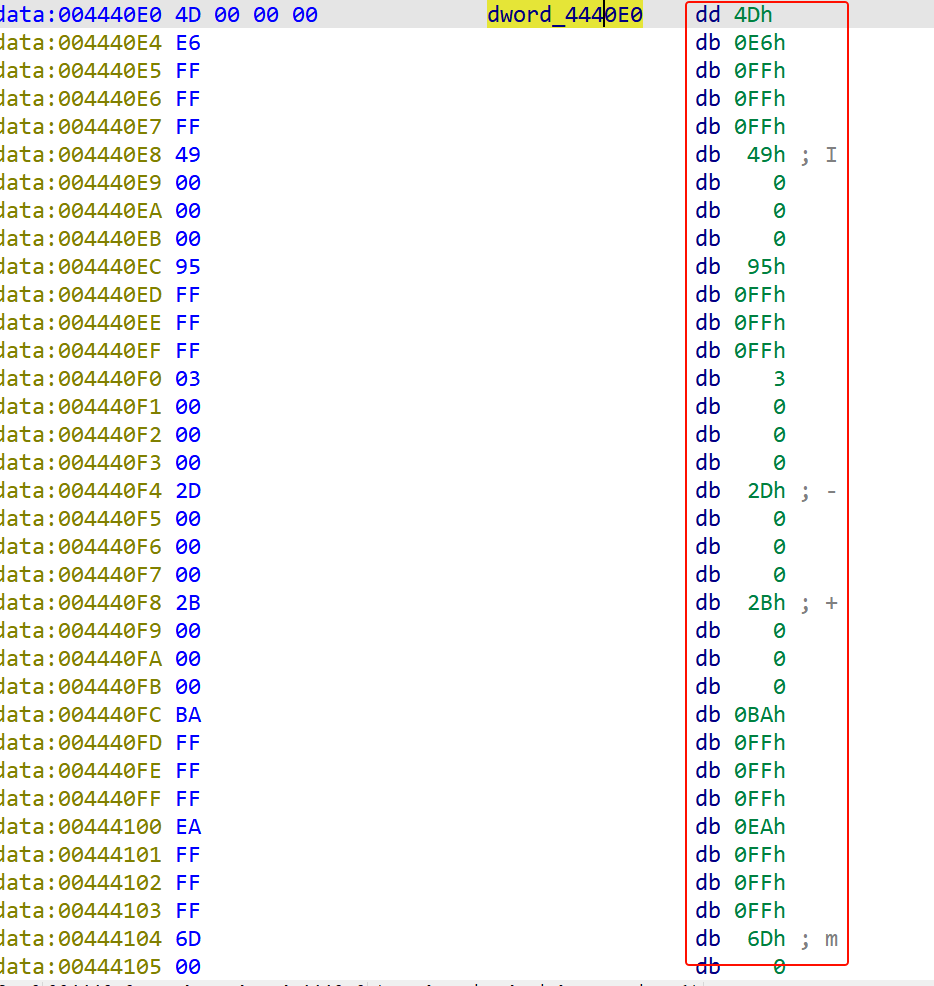
dword_4440E0[v2]里面存放的就是密文,我们提取出来是
1 | [0x0000004D, 0xFFFFFFE6, 0x00000049, 0xFFFFFF95, 0x00000003, 0x0000002D, 0x0000002B, 0xFFFFFFBA, |
写出exp,这里引用这位大佬的博客的脚本 https://zach0ry-zzh.github.io/2025/07/14/HNCTF-2022-WEEK4-flower-plus/
异或脚本
1 | a=[0x0000004D, 0xFFFFFFE6, 0x00000049, 0xFFFFFF95, 0x00000003, 0x0000002D, 0x0000002B, 0xFFFFFFBA, |
RC4解密脚本
1 | def to_unsigned_32bit_and_byte(n): |
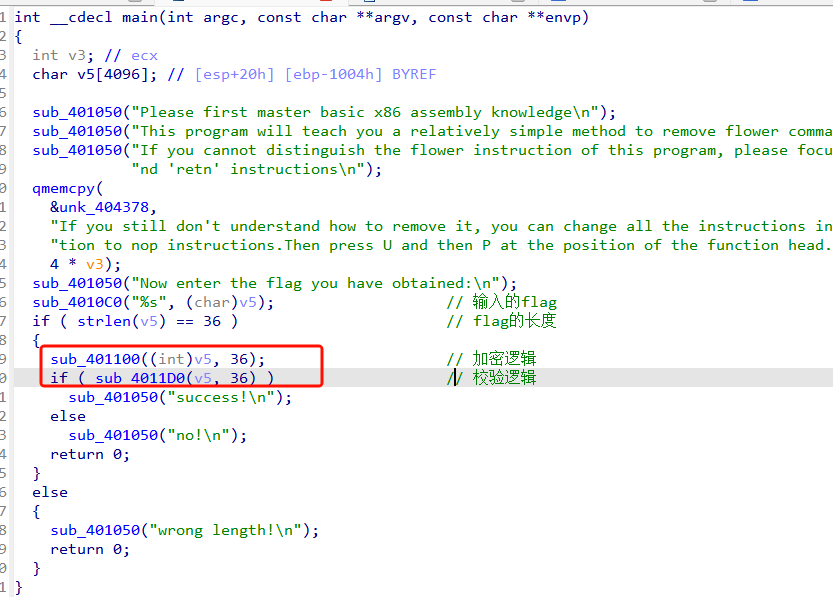
例题2:NewStar-Dirty_flowers
使用IDA打开,看到main函数里面爆红,一眼花指令

我们看这里的汇编指令
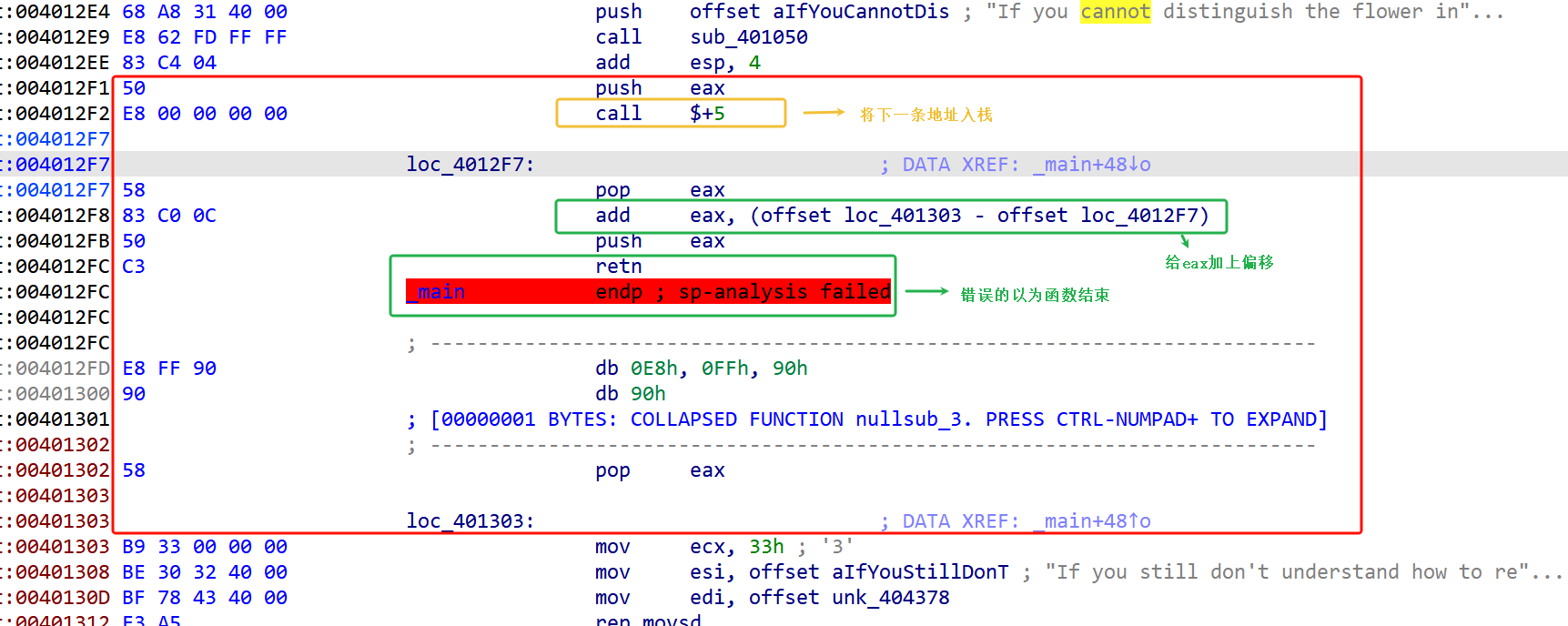
这是call指令+ret指令构成可以跳转任意地址的花指令。
call $+5 实际是 call 到当前地址加 5 的位置,也就是 调用下一条指令
就相当于call 0x4012F7,将它的下一条地址(也就是 0x4012F7)作为返回地址压入栈中,并且跳转到0x4012F7继续执行。
在 loc_4012F7里, pop eax 是从栈顶取出内容放到 eax,也就是拿到了刚刚 call 压栈的返回地址 0x4012F7
add eax, (offset loc_401303 - offset loc_4012F7)是给eax上的地址加上从offset loc_401303 到 offset loc_4012F7的偏移量,新的地址就是0x401303。
push eax,就把这个新的地址重新压入栈中
ret,是从栈顶弹出这个新的返回地址。
那么红色筐住的部分都是这个程序跳过的,它相当于直接执行了0x401303部分的指令。我们可以把这部分给 nop 掉。
nop后的样子
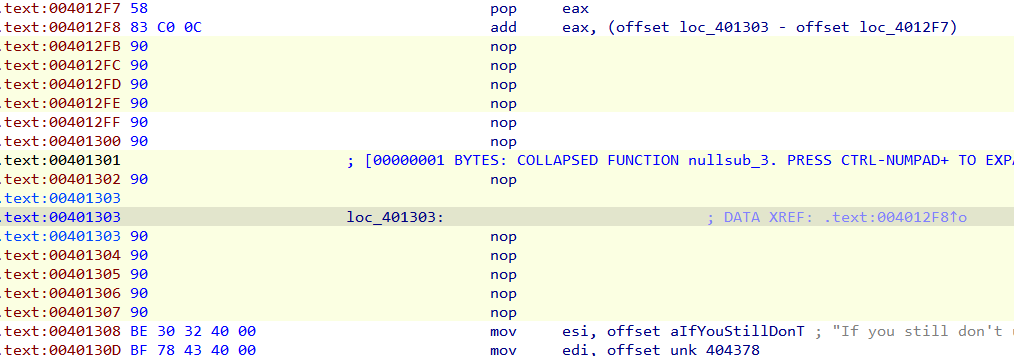
我们选中main函数头,按U进行解除定义,找到函数尾然后P重新定义一下,按F5进行反编译
发现还有一处花指令,这个与上面的一摸一样,处理方法也是一样的
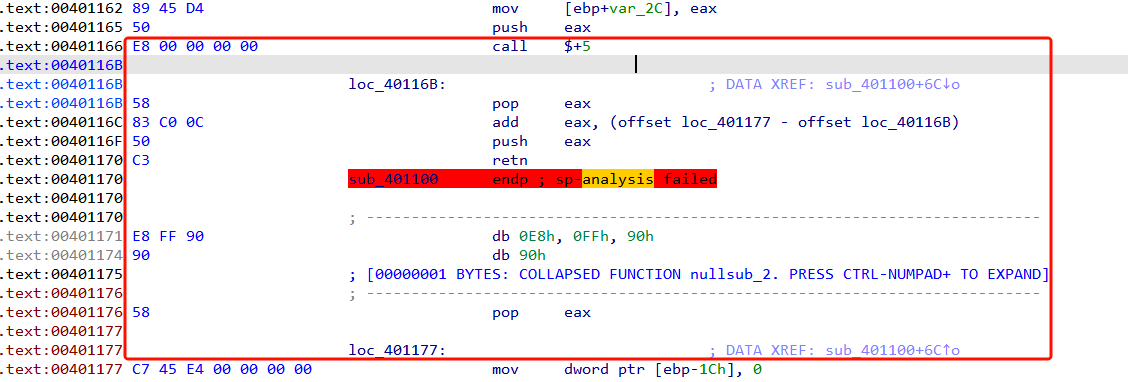
将红色框住的都nop掉。然后相同的方式重构函数,就能反汇编成功了。
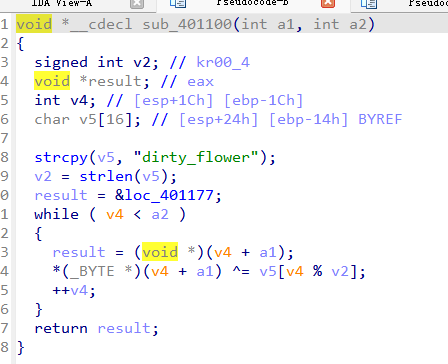
这是按位异或加密
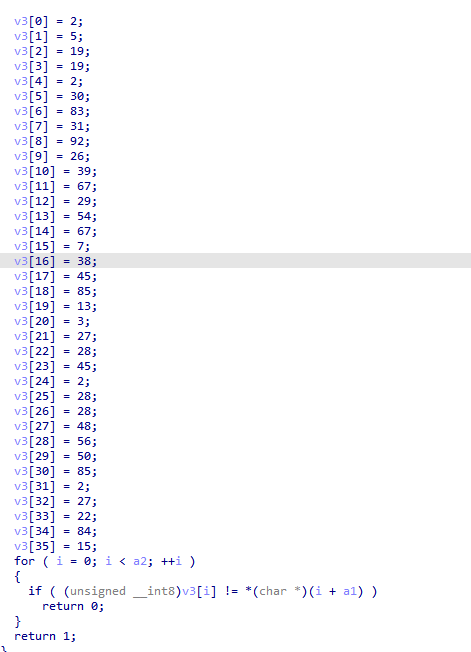
这是输入验证函数。
直接写出exp,解出flag
1 | lis = [0x02, 0x05, 0x13, 0x13, 0x02, 0x1e, 0x53, 0x1f, 0x5c, 0x1a, 0x27, 0x43, 0x1d, 0x36, 0x43, |
形式二:永真永假
通过设置永真或者永假的,导致程序一定会执行,由于ida反汇编会优先反汇编接下去的部分(false分支)。也可以调用某些函数会返回确定值,来达到构造永真或永假条件。
例题:NSS-[HZNUCTF 2023 final]虽然他送了我玫瑰花
使用IDA打开后,我们并不能反汇编main函数,这就是main函数里面插花了
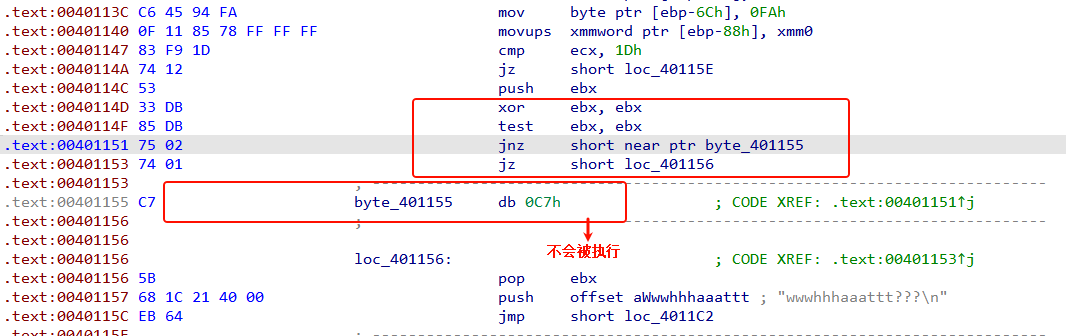
我们发现 ebx是0,ZF寄存器是1。 jnz short near ptr byte_401155 这个指令永远都不会被跳转,而jz short loc_401156这个指令一定会被跳转。所以0xC7就会被跳过,不执行。我们直接将它nop掉,然后从main函数头选中,一直到retn结束,直接按P进行重新定义,main就能F5进行反汇编了。

到这里花指令已经去除完毕,下面进行逻辑分析
下断点到 给v8赋值的那一行,动态分析得到密文的值,密文从0x7F开始,一直到0xFA结束
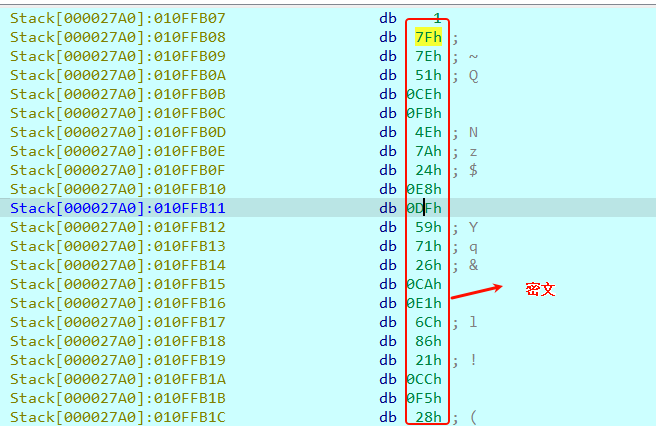
验证逻辑的那一行中&v9 + v4 表示从 v9 开始偏移 v4,也就是说:*(&v9 + v4) 是访问内存中 v9 后面第 v4 个字节,这个就是密文。
得到密文后我们看如何进行加密的,点开40117E这个加密函数,我们发现里面有五个函数如下所示
flag[i] 被传入不同的函数处理,结果保存到 v8[i] 中,funcs_40117E[i % 5u]:函数指针数组 funcs_40117E 中的一个函数,第 i mod 5 个
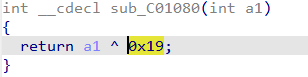
当 i mod 5==0时,运行这个函数,flag[i]^0x19,解密还是一样的。
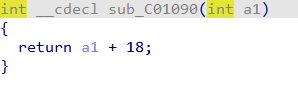
当 i mod 5==1时,运行这个函数,flag[i]+18,那么解密就是flag[i]-18。
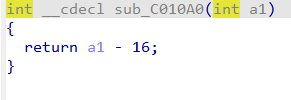
当 i mod 5==2时,运行这个函数,flag[i]-16,那么解密就是flag[i]+16。
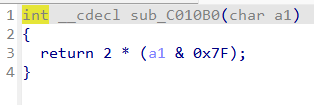
乘以2就是左移1位,等价于(a1 & 0x7F) << 1
当 i mod 5==3时,运行这个函数,( flag[i] & 0x7F) << 1,那么解密就是(flag[i]>>1)& 0xff,0xff的作用:保留整数的最低 8 位(即 0~255 范围)
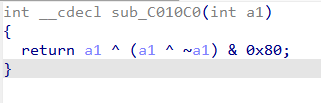
这里,符号的优先级是 ‘ ~ ‘(按位取反) > ‘&’(按位与) > ‘^’(异或)
~a1 是按位取反,a1 ^ ~a1 会把每一位变成 1,0xFF=1111 1111。所以表达式就变成了a1 ^ (0xFF & 0x80) = a1 ^ 0x80
当 i mod 5==4时,运行这个函数,flag[i]^0x80,解密还是一样的。
写出exp
1 | enc = [ |
结语
我觉得这篇文章总结的还有很多不足,但是希望能给学习花指令的伙伴们一些帮助。我个人认为带有一些对应的例题可能会更好理解。这些差不多是一些简单的花指令,其实对抗花指令最好的方式还是要读懂这些汇编代码,然后知道哪里是被跳转的,然后逐个nop掉。


