
题目复现2
题目复现2
1.BUU-[FlareOn6]Overlong
解题思路
老步骤,先查壳,发现是无壳32位,直接IDA打开。
发现函数特别少,还挺简洁的。
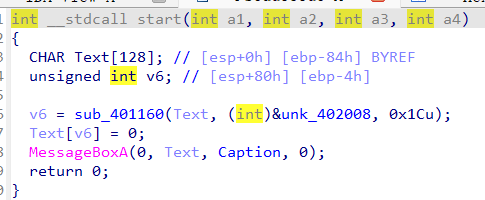
我们能分析出来,Text是我们要的flag,最终会使用弹窗输出出来,我们可以直接动调看看,发现是
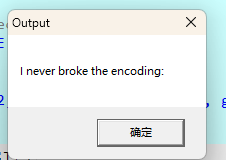
这个弹窗上的像是没有输出完一样,我们就查看unk_3D2008的数据有多少。
发现这个数据其实有很多很多
起始地址是0x003D2008
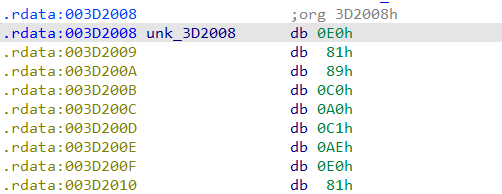
结束地址是0x003D20B7

我们可以使用计算器来计算它的大小,得出结果是0xAF

转到汇编看一下,现在已经清楚是分配的内存空间太小,以至于在进行sub_3D1160函数加密的时候,只能实现0x1C个字节,我们应该把0x1C改成0xAF,这样就能输出完整了。

如何改呢,在汇编成面push 1Ch 处打上断点,然后进行调试。
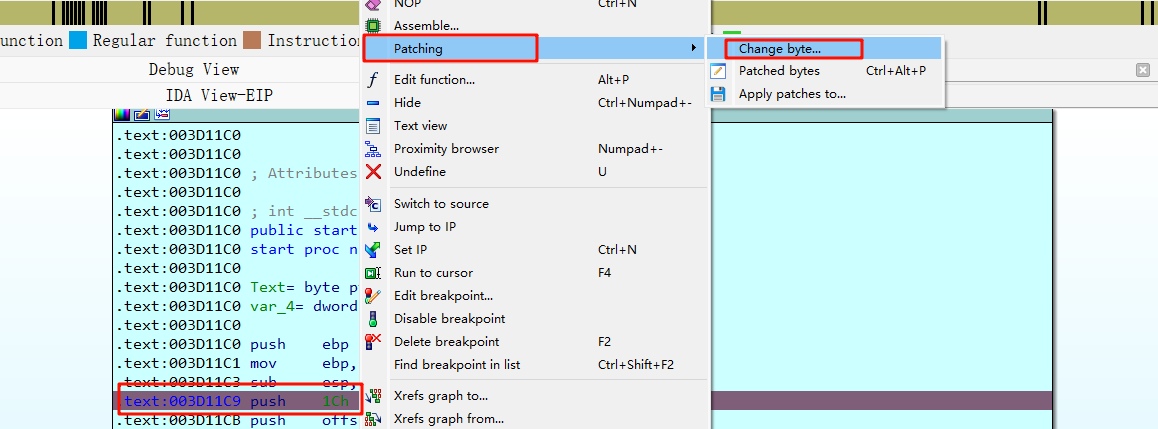
我们可以直接将1C patch 成 AF
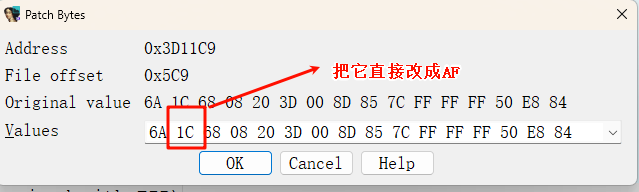
改完后,我们直接按F9让它运行到弹窗,完整的flag就出来了。
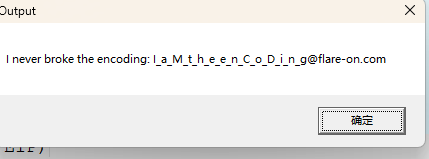
记录
本题是给数据分配的内存空间太小,导致flag不完整,可以通过patch来修改内存大小。
2.BUU-[羊城杯 2020]easyre
解题思路
无壳使用IDA打开,分析主函数
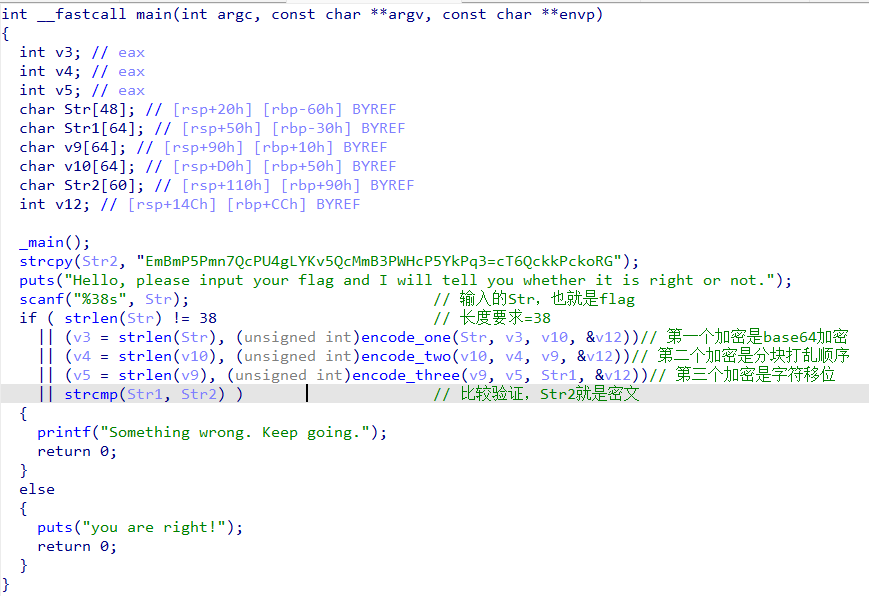
大致的逻辑已经清楚,知道了flag是经过三层加密得到了str2这个密文。我们应该逆向分析,从第三个加密函数开始看起。

这个是对v9按照字符分类加密的,最后得到密文是Str1,也就是Str2。我们进行逆行分析,对Str2分别对应字符分类解密就能得到v9。
第三个加密方式是凯撒加密 +3,将字母或数字向右平移3位。解密就是凯撒加密 -3就 ok了。
但是要注意的是:如果直接减可能会变成负数,比如 'A' - 3 → '>'(非法),所以我们加上模数再取余
解密:这里先让c 看作是密文的角标
大写字母:(ord(c) - ord('A') - 3 + 26) % 26 + ord('A')
小写字母:(ord(c) - ord('a') - 3 + 26) % 26 + ord('a')
数字:(ord(c) - ord('0') - 3 + 10) % 10 + ord('0')
然后分析第二个加密函数
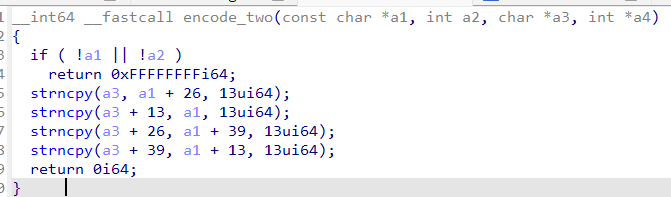
这个函数中 a3 是 v9 , a1是 v10,a2 是 v10的长度。我们从上一个加密函数中能解出 v9。
这个加密的过程是:
将a1的第0位到第13位赋给a3的第13到26位
将a1的第13位到第26位赋给a3的第39到52位
将a1的第26位到第39位赋给a3的第0到13位
将a1的第39位到第52位赋给a3的第26到39位
那我们解密时要将 v9 每13位一组分成4组,然后按照这个来重新组合。那我们就能得到v10了。
a1[00:13] ← a3[13:26]
a1[13:26] ← a3[39:52]
a1[26:39] ← a3[00:13]
a1[39:52] ← a3[26:39]
接着看第一个加密函数

根据这些特征,可以看出来这个是个base64加密,关键是找到表,表点击alphabet就能看到,这个表就是base64加密标准表,直接解密就好。a3就是v10。
exp
1 | ##decode_three |
记录
考了凯撒加密,分组排列和base64三种加密方法。
3.BUU-[WUSTCTF2020]level4
解题思路
这个题是ELF文件,我们先用IDA打开看看
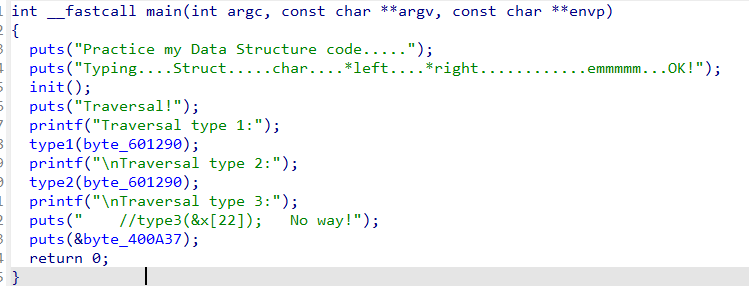
这段程序是二叉树 遍历(Traversal),给了三种遍历方式,type1,type2和 type3。我们可以从程序里得到type1和type2的函数内容,但不知道type3进行了什么遍历。我们先看看这些函数都是什么用处。
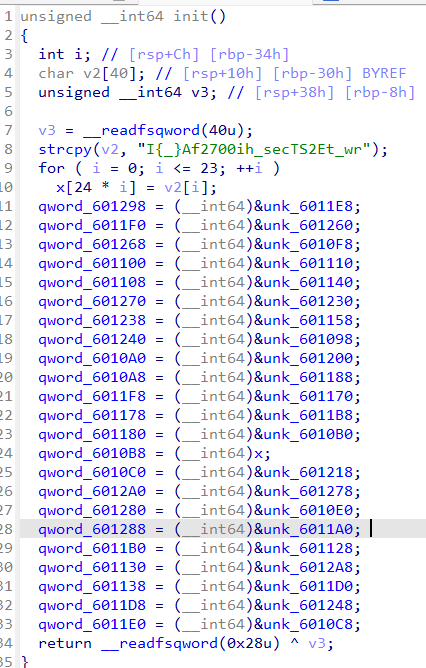
init() 函数的作用是初始化一个数据结构,这里是树结构,并从字符串 "I{_}Af2700ih_secTS2Et_wr" 中提取字符并写入结构数组 x。它设置大量全局变量指向特定结构体地址,构建“二叉树”的指针结构。
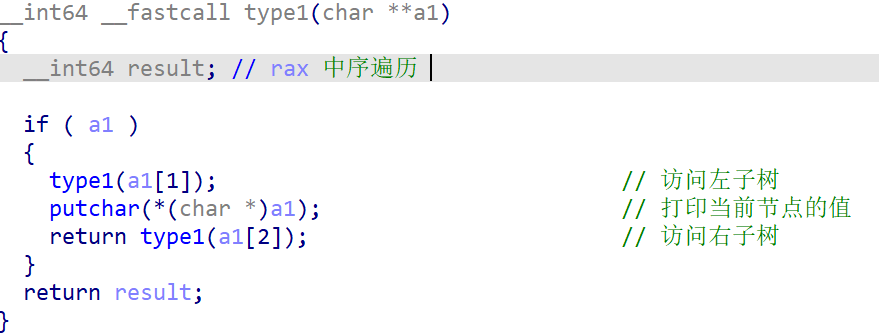
看看type1,这是中序遍历,中序:左根右。
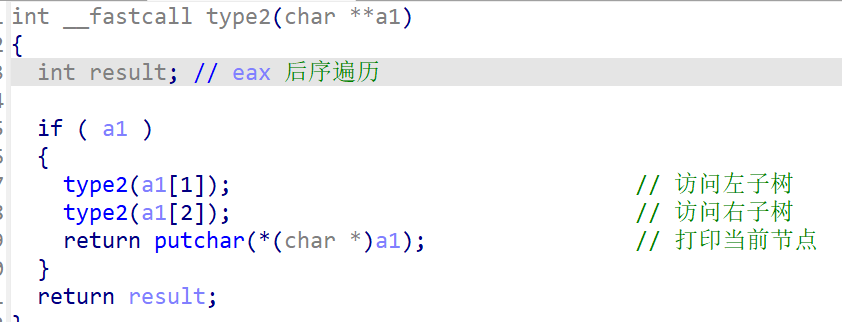
看看type2,这是后序遍历,后序:左右根
我们在虚拟机上运行可以知道结果
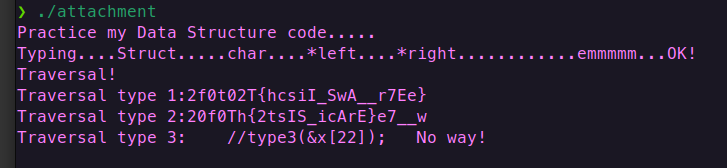
但是发现这两种遍历得到的都不是flag,那就是type3遍历,应该是前序遍历。我们只要已知一个二叉树的中序遍历(In-order)和后序遍历(Post-order)序列,就可以唯一确定这棵二叉树的结构,从而也就能推出其前序遍历(Pre-order)结果。
exp
1 |
|
记录
考了二叉树的三种遍历方式,前序,中序和后序。前序:根左右,中序:左根右,后序:左右根
而且给定前序遍历+中序遍历或者给定了中序遍历+后序遍历,二叉树的构造方法都是唯一的
4.[GUET-CTF2019]number_game
解题思路
拿到文件后先查壳,这个没有壳,ELF64位,直接放入IDA进行静态分析。
进入主函数对其进行分析
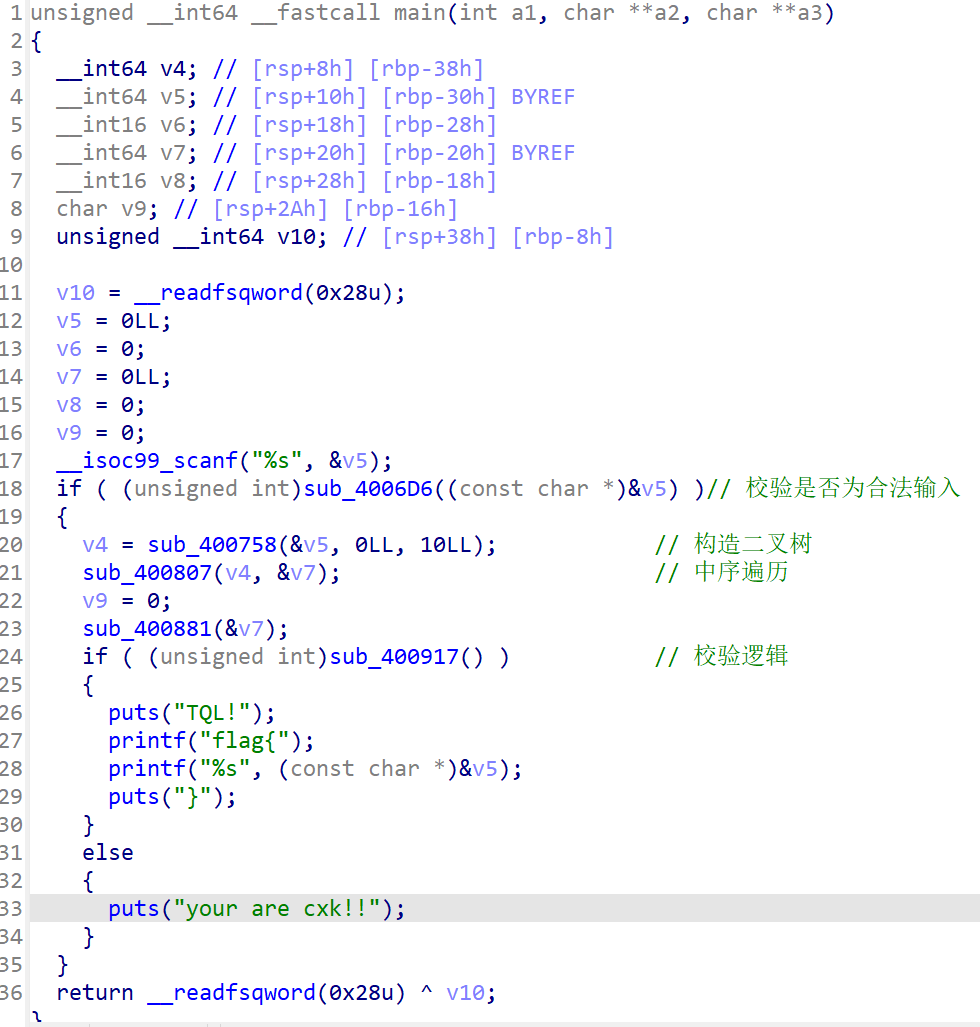
这个 main 函数的核心流程是输入一段字符串,对其进行合法性检查、二叉树构建与遍历处理,并通过一系列检查逻辑,决定是否输出 flag。我们先按照顺序来分析,先看校验是否为合法输入的函数。
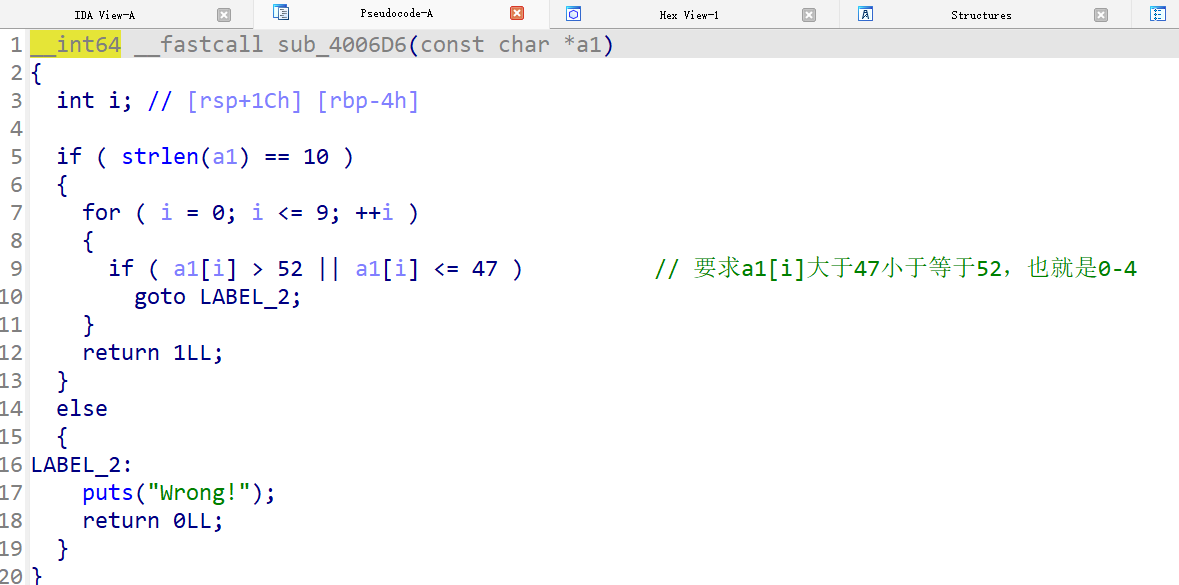
这个函数是遍历a1的值,确保a1的值在0~4范围内,否则输出Wrong!
然后分析构造二叉树的函数sub_400758(&v5, 0, 10):将输入字符串转为一棵二叉树,返回一个指向根节点的指针(即 _QWORD *)
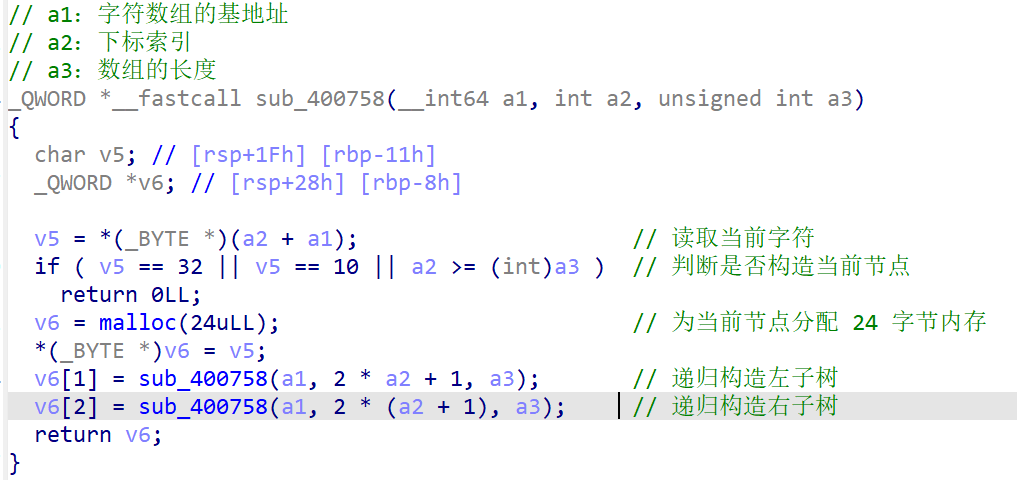
这个函数返回一个 _QWORD *,即一个指向二叉树节点的指针,每个节点占用 24 字节。v5:用于暂存当前数组中的字符。v6:将作为当前新建的树节点指针。
第一步:将地址 (a1 + a2) 处的字节读取出来赋值给 v5。 意思是从数组中取出当前下标 a2 的字符。
第二步:判断是否构造当前节点,如果当前字符是 ' '(ASCII 32)或 '\n'(ASCII 10),就不创建节点(这些字符被视为空节点);
或者当前索引越界(a2 >= a3),返回空指针。所以此函数跳过空格、换行、或越界位置的内容。
第三步:分配内存,为当前节点分配 24 字节内存。
第四步:设置当前节点的值。*(_BYTE *)v6 = v5;
第五步:递归构造左子树,左子节点的索引是 2 * a2 + 1,符合完全二叉树(堆)数组索引规律。
第六步:递归构造右子树,右子节点的索引是 2 * (a2 + 1),即 2 * a2 + 2。
第七步:返回当前节点指针。
然后分析中序遍历函数sub_400807(v4, &v7):对树进行中序遍历,把结果保存在某个缓冲区中(v7 开头的位置)
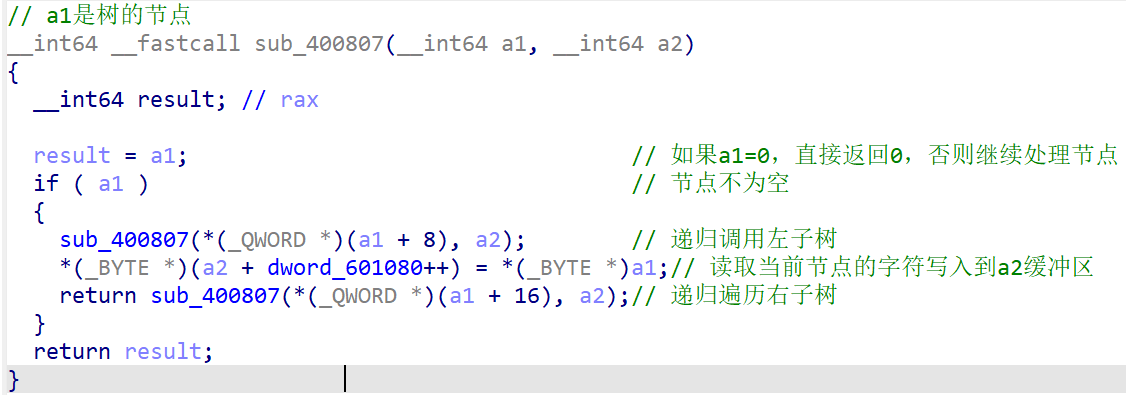
a1:指向一个结构体或对象的指针,代表二叉树形结构中的一个节点。a2:一个缓冲区的地址,用来写入某种输出数据。
如果当前节点不为空,就递归地遍历其左子树、处理当前节点、再遍历右子树。这实现了中序遍历。其节点结构为:
*(_QWORD *)(a1 + 8) = 左子树指针
*(_QWORD *)(a1 + 16) = 右子树指针
*(_BYTE *)a1 = 当前节点值
然后分析一下 sub_400881(&v7)函数
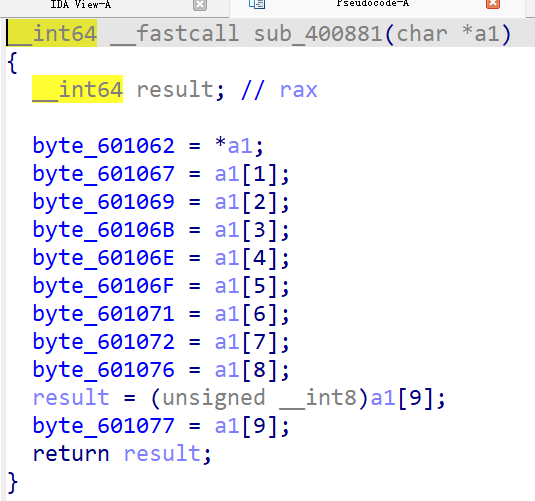
它的作用是把输入字符串 a1 中的前 10 个字节依次复制到某些特定的全局变量地址(全局缓冲区)中。也就是把中序遍历后的结果放在了缓冲区里面,点进去看看却发现这些都是 '#' ,我们需要知道这些具体的数据。
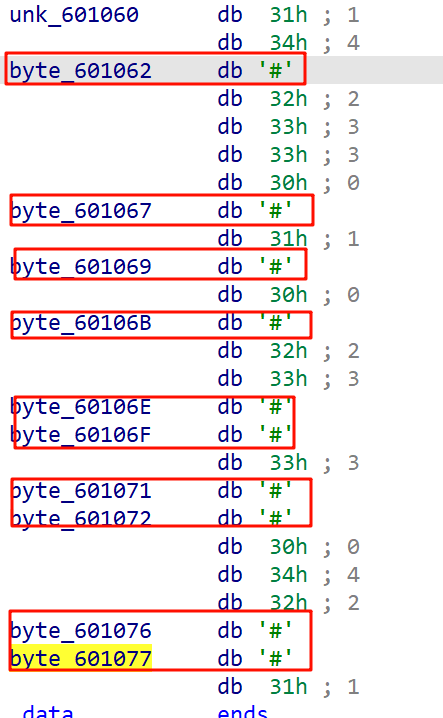
我们先继续往下进行分析,现在要分析sub_400917()函数,这是最后的校验逻辑

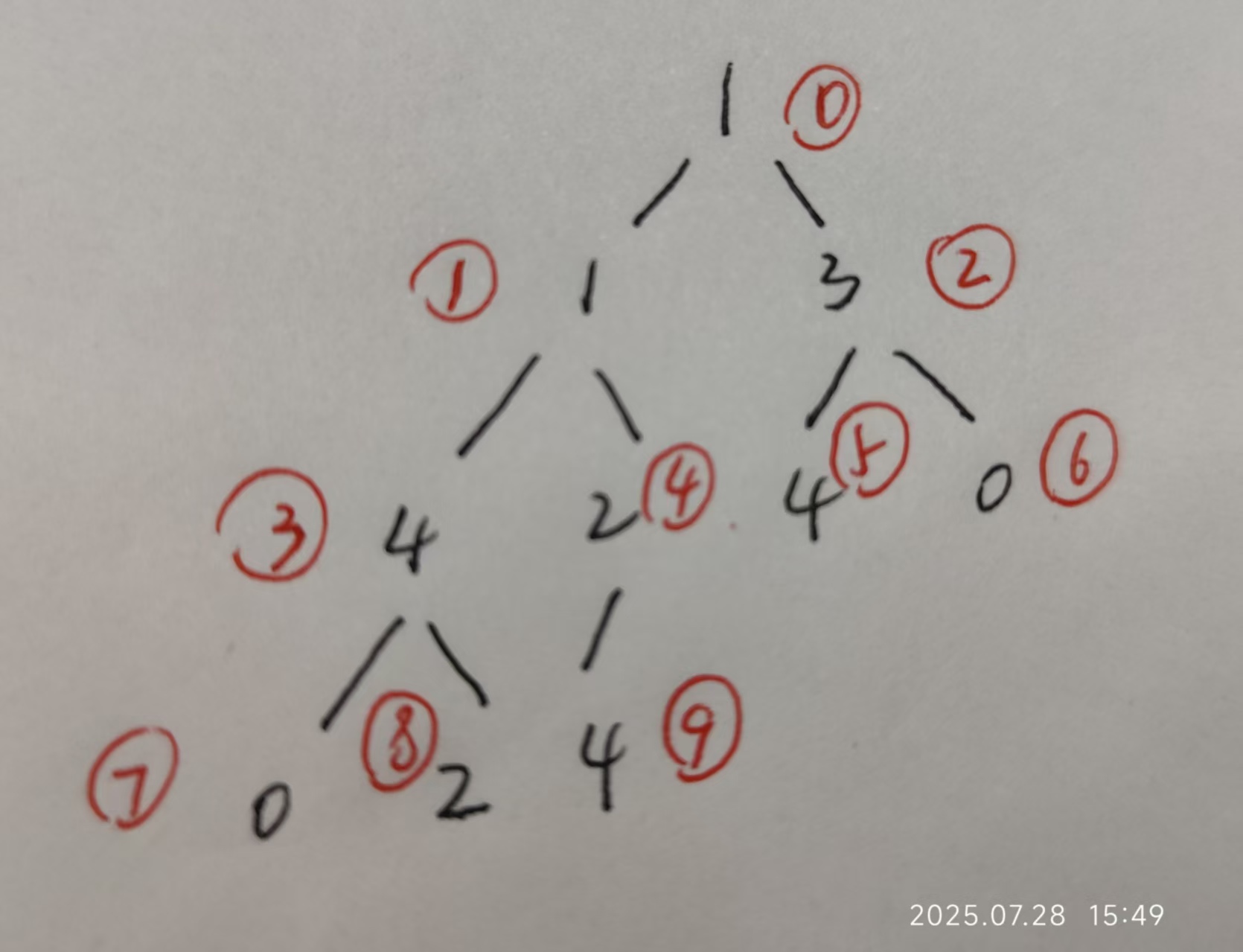
很明显的这是从unk_601060缓冲区开始读取25个字节,把它看作5x5的矩阵来分析,逻辑是对于每一行和每一列都要求元素不相同,简单来说,这就是一个数独游戏,我们可以根据这个校验逻辑来算出中序遍历的结果是什么。这里我选择手动计算。

我们现在就知道了这个中序遍历后的结果是0421421430,那么我们现在要求的flag是v5,也就是输入构成二叉树的数据,我们只需要得出这个二叉树中序遍历访问的节点顺序,然后一一映射就能得出flag。
这里可以通过写脚本得出中序遍历的节点顺序,也可以动调。动调的方法参考
https://blog.csdn.net/qq_45892237/article/details/115664816
节点顺序是[7, 3, 8, 1, 9, 4, 0, 5, 2, 6],一一映射举个例子,比如第一个节点是7,那么节点为7储存的就是中序遍历后的第一个数据为’0’,我们要将这个0移动到下标为7的位置。也就是以这个节点顺序为新的索引重新排列得到原来的数据。
exp
1 | def inorder_indices(pos, n): |
记录
考了二叉树的遍历和数独
5.BUU-[ACTF新生赛2020]SoulLike
解题思路
先查壳,这个无壳,直接IDA进行分析主函数
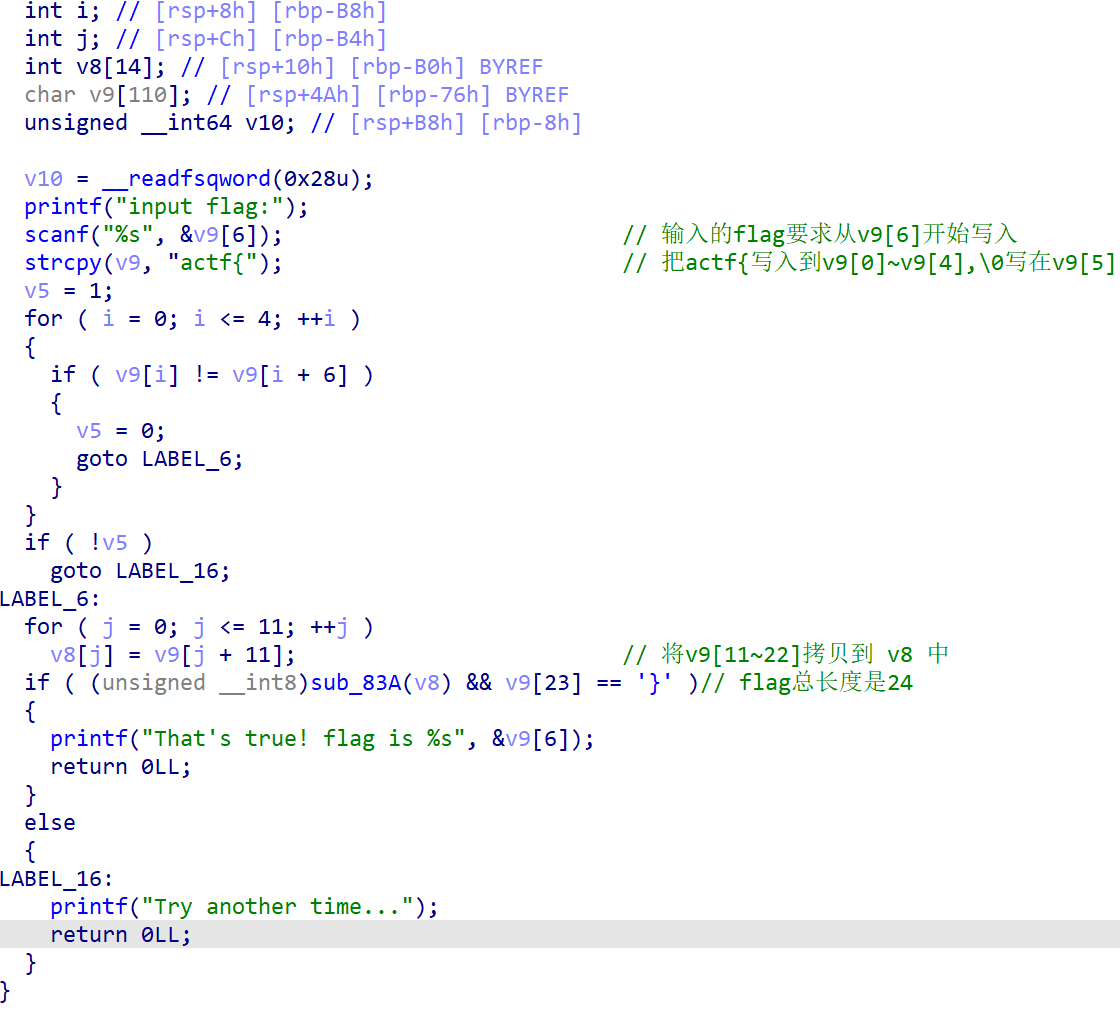
这个大致逻辑是将flag从v9[6]的位置开始输入,将 “actf{“ 写入到v9[0]~v9[4]中,\0写在v9[5]中。然后进入前缀是否相等的判断中。
v5先设为1,进入判断,如果v9[i]!=v9[i+6],那么v5=0,跳转到LABEL_6,当循环结束时,会执行!v5这个条件跳转,是满足的,会跳转到LABEL_16,这就说明了本质上是要求它们是相等的。
如果v9[i]==v9[i+6],也就是字符串是这个形式actf{actf{xxxxx……,v5还是等于1,!v5是0,不会跳转到LABEL_16,而是继续往下执行到LABEL_6。
进入到LABEL_6的校验逻辑中,v8是v9[11]~v9[22],也就是除去了flag的前缀头,是flag真正内容的部分。我们要分析sub_83A函数,但是发现了这个函数太大,IDA无法反编译,该怎么办呐???
解决办法:
我们找到IDA目录,打开 IDA 安装目录下的 IDA/cfg/hexrays.cfg 文件,可能路径会有不同,直接搜索就可以
找到配置项:
1 | MAX_FUNCSIZE=64 |
修改为更大的值:
1 | MAX_FUNCSIZE=1024 |

然后重启IDA,经过很长一段时间就能成功反编译了
发现sub_83A函数竟然有3000多行的异或加密,密密麻麻是我的自尊~
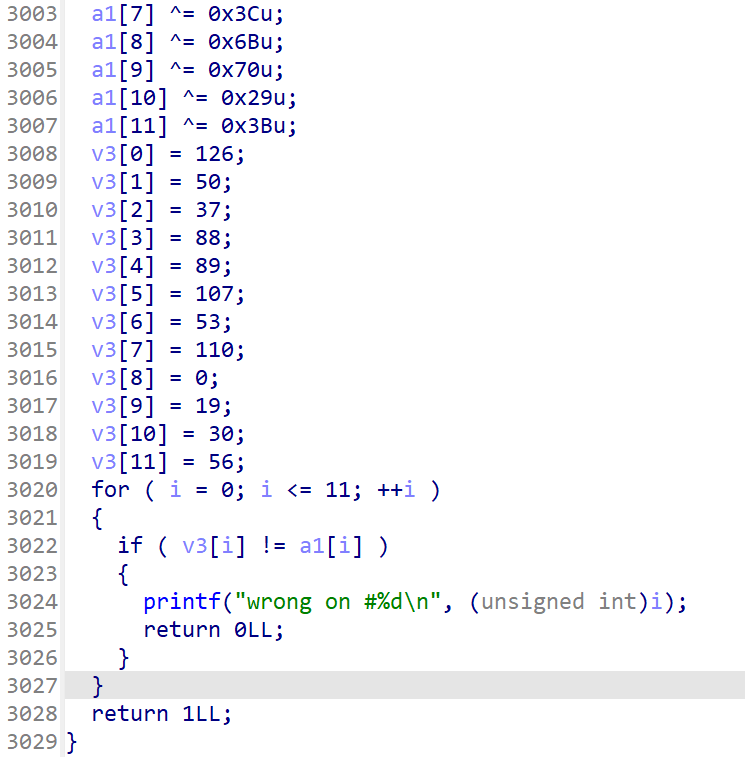
拖到最后知道这个校验逻辑,加密后的flag内容与v3相等,那么可以考虑的是爆破,这里直接用的大佬的exp
https://blog.csdn.net/2201_76139143/article/details/132511141
exp
1 |
|
记录
知道一个函数过大IDA无法反编译时可以修改配置文件hexrays.cfg中MAX_FUNCSIZE=64,把64换成更大的数,然后就能反编译出来了。这道题可以爆破处理。


