题目复现3 1.NSS-[HNCTF 2022 WEEK2]getflag 这道题比较简单,有多种解法
第一种 patch
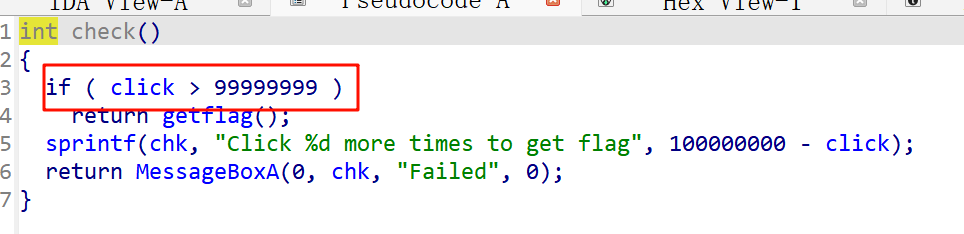
直接搜索字符串,通过交叉引用找到 点击 的函数,重点在这个99999999
转到汇编看看,在cmp这里打上断点,动态调试,在动调中去patch
有两种patch思路
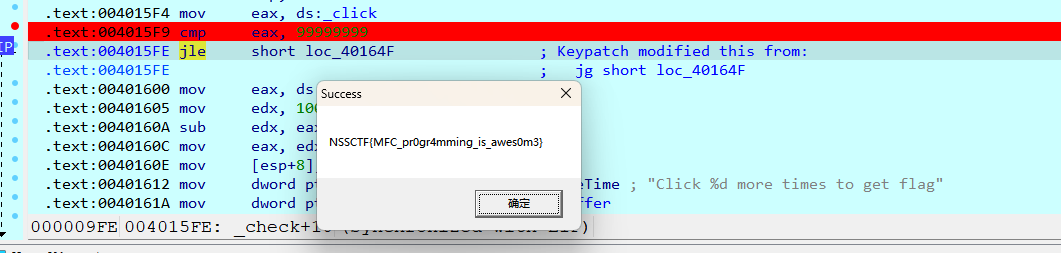
1.把 jg 改成 jle
原本代码 :jg short loc_40164F_click > 99999999 就跳转,执行 call _getflag。
修改后 :jle short loc_40164F_click <= 99999999 就跳转。
补充一下跳转指令:
jg (jump if greater)
含义 :如果 a > b,则跳转。条件 :ZF = 0 且 SF = OF。
ZF=0 → 结果不相等。SF=OF → 有符号比较时,结果大于。
jle (jump if less or equal)
含义 :如果 a <= b,则跳转。条件 :ZF = 1 或 SF ≠ OF。
ZF=1 → 两数相等。SF≠OF → 有符号比较时,结果小于。
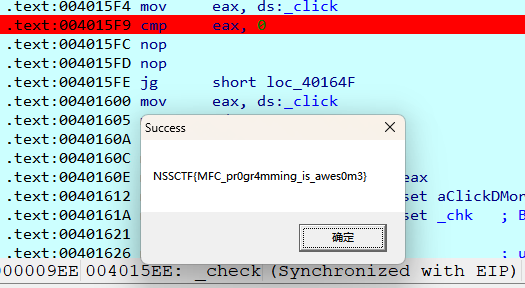
2.把99999999改成0或者其他很小的数
我改成的0,这样之点击1次就满足条件可以跳转了,得到flag。
第二种 静态分析
前面不管怎样都是要跳转到getflag()函数里面,我们可以直接找到它,进行分析
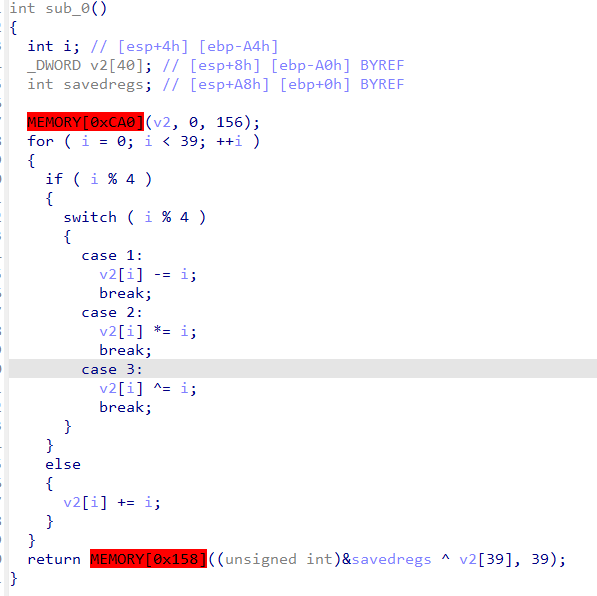
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 int getflag () { CHAR Text[128 ]; _BYTE v2[42 ]; v2[0 ] = -28 ; v2[1 ] = 53 ; v2[2 ] = 53 ; v2[3 ] = 52 ; v2[4 ] = 69 ; v2[5 ] = 100 ; v2[6 ] = -73 ; v2[7 ] = -44 ; v2[8 ] = 100 ; v2[9 ] = 52 ; v2[10 ] = -11 ; v2[11 ] = 7 ; v2[12 ] = 39 ; v2[13 ] = 3 ; v2[14 ] = 118 ; v2[15 ] = 39 ; v2[16 ] = 67 ; v2[17 ] = -42 ; v2[18 ] = -42 ; v2[19 ] = -106 ; v2[20 ] = -26 ; v2[21 ] = 118 ; v2[22 ] = -11 ; v2[23 ] = -106 ; v2[24 ] = 55 ; v2[25 ] = -11 ; v2[26 ] = 22 ; v2[27 ] = 119 ; v2[28 ] = 86 ; v2[29 ] = 55 ; v2[30 ] = 3 ; v2[31 ] = -42 ; v2[32 ] = 51 ; v2[33 ] = -41 ; dec(v2, Text); return MessageBoxA(0 , Text, "Success" , 0 ); }
看到dec,进去看看进行了什么解密操作
这都是解密脚本了,也不用再逆向了哈哈,不过要注意的是,如果使用python来写脚本,enc的一些数值是负数,一定要 &0xff
1 2 3 4 5 6 7 8 enc = [-28 , 53 , 53 , 52 , 69 , 100 , -73 , -44 , 100 , 52 , -11 , 7 , 39 , 3 , 118 , 39 , 67 , -42 , -42 , -106 , -26 , 118 , -11 , -106 , 55 , -11 , 22 , 119 , 86 , 55 , 3 , -42 , 51 , -41 ] flag='' for i in range (len (enc)): flag+=chr (((enc[i] & 0xff ) >>4 | (enc[i] & 0xff ) <<4 ) & 0xff ) print (flag)
2.[HNCTF 2022 Week1]Little Endian 这道题的逻辑很简单,就是异或,主要是要考虑端序问题
1 2 3 4 5 6 7 enc=[0x51670536 , 0x5e4f102c , 0x7e402211 , 0x7c71094b , 0x7c553f1c , 0x6f5a3816 ] flag=b'' for c in enc: x=c^0x12345678 flag+=x.to_bytes(4 ,"little" ) print (flag)
enc 里面每个元素都是 32位整数(4个字节的数据),本质上是4个字节的组合,组合方式一般两种:大端序和小端序
在IDA里面一般都是小端序存储.
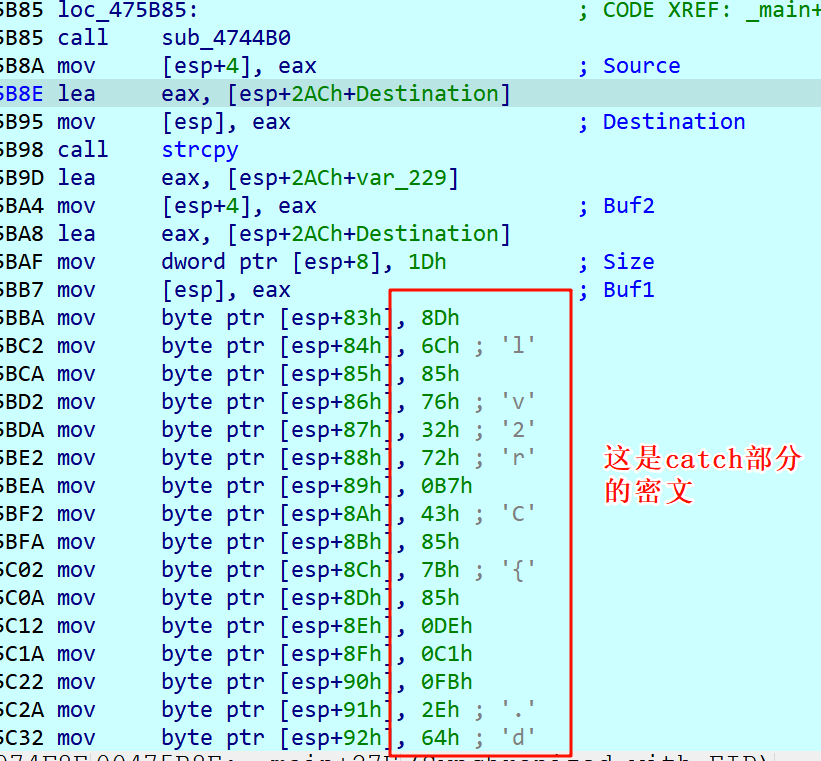
3.[LitCTF 2023]程序和人有一个能跑就行了 由于IDA识别C++的 try/catch 结构时经常不完整,这就给了出题人隐藏真正的密文或key的机会。
x86 (32 位) → SEH + C++ EH metadata 在 .rdata
x64 (64 位) → 异常处理表单独放在 .pdata、.xdata
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def rc4 (data,key ): S = list (range (256 )) j = 0 out = [] for i in range (256 ): j = (j + S[i] +key[i % len (key)]) % 256 S[i],S[j] = S[j],S[i] i=j=0 for c in data: i = (i+1 ) % 256 j = (j+S[i]) % 256 S[i],S[j] = S[j],S[i] K=S[(S[i] + S[j])% 256 ] out.append(c ^ K) return bytes (out) key = b"litctf" enc = [0x8d , 0x6c , 0x85 , 0x76 , 0x32 , 0x72 , 0xb7 , 0x43 , 0x85 , 0x7b , 0x85 , 0xde , 0xc1 , 0xfb , 0x2e , 0x64 , 0x07 , 0xc8 , 0x5f , 0x9a , 0x35 , 0x18 , 0xad , 0xb5 , 0x15 , 0x92 , 0xbe ,0x1b ,0x88 ] decrypted = rc4(enc,key) print ("解密:" , decrypted)print (decrypted.decode())
4.XYCTF2024-何须相思煮余年 拿到题目附件后是一串16进制字符串,为什么没有代码呀?
这个给的就是机器码(opcode)序列,我们把0x前缀都去掉,每个字节都保留空格分隔。
一个将机器码转成汇编语言的在线网站:https://defuse.ca/online-x86-assembler.html
但是只看汇编有点麻烦捏~
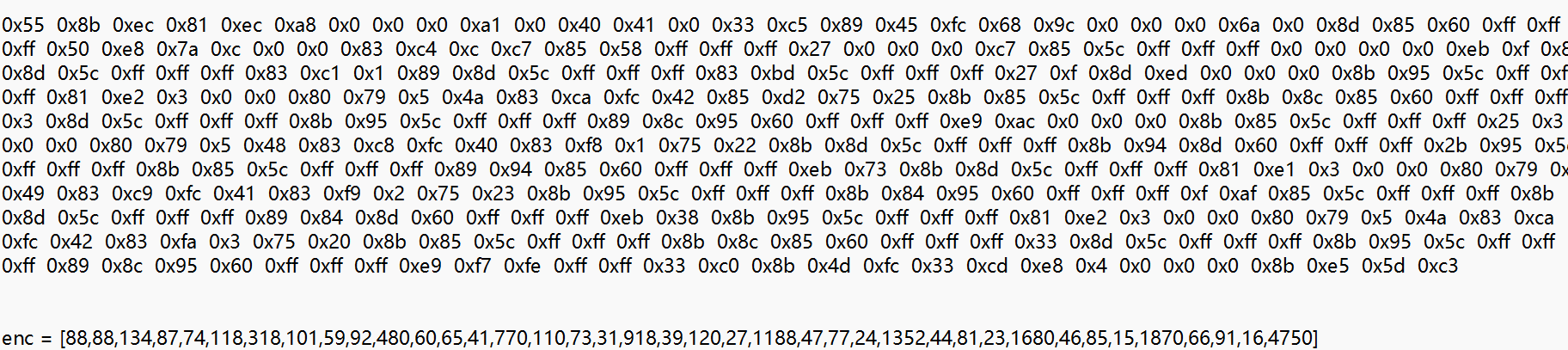
1 55 8b ec 81 ec a8 00 00 00 a1 00 40 41 00 33 c5 89 45 fc 68 9c 00 00 00 6a 00 8d 85 60 ff ff ff 50 e8 7a 0c 00 00 83 c4 0c c7 85 58 ff ff ff 27 00 00 00 c7 85 5c ff ff ff 00 00 00 00 eb 0f 8b 8d 5c ff ff ff 83 c1 01 89 8d 5c ff ff ff 83 bd 5c ff ff ff 27 0f 8d ed 00 00 00 8b 95 5c ff ff ff 81 e2 03 00 00 80 79 05 4a 83 ca fc 42 85 d2 75 25 8b 85 5c ff ff ff 8b 8c 85 60 ff ff ff 03 8d 5c ff ff ff 8b 95 5c ff ff ff 89 8c 95 60 ff ff ff e9 ac 00 00 00 8b 85 5c ff ff ff 25 03 00 00 80 79 05 48 83 c8 fc 40 83 f8 01 75 22 8b 8d 5c ff ff ff 8b 94 8d 60 ff ff ff 2b 95 5c ff ff ff 8b 85 5c ff ff ff 89 94 85 60 ff ff ff eb 73 8b 8d 5c ff ff ff 81 e1 03 00 00 80 79 05 49 83 c9 fc 41 83 f9 02 75 23 8b 95 5c ff ff ff 8b 84 95 60 ff ff ff 0f af 85 5c ff ff ff 8b 8d 5c ff ff ff 89 84 8d 60 ff ff ff eb 38 8b 95 5c ff ff ff 81 e2 03 00 00 80 79 05 4a 83 ca fc 42 83 fa 03 75 20 8b 85 5c ff ff ff 8b 8c 85 60 ff ff ff 33 8d 5c ff ff ff 8b 95 5c ff ff ff 89 8c 95 60 ff ff ff e9 f7 fe ff ff 33 c0 8b 4d fc 33 cd e8 04 00 00 00 8b e5 5d c3
我们可以新建一个文件去掉文件后缀名,把它放到010里面,把上面的机器码序列全部粘进去。就得到了一个二进制文件,我们可以直接把它放到IDA里面,进行分析。这样方便的多,不仅可以看到机器码转成的汇编指令,还可以选中整个函数部分按P重构,就能得到反编译的加密逻辑啦,还是IDA👍
直接写出解密脚本
python:
1 2 3 4 5 6 7 8 9 10 11 12 enc = [88 ,88 ,134 ,87 ,74 ,118 ,318 ,101 ,59 ,92 ,480 ,60 ,65 ,41 ,770 ,110 ,73 ,31 ,918 ,39 ,120 ,27 ,1188 ,47 ,77 ,24 ,1352 ,44 ,81 ,23 ,1680 ,46 ,85 ,15 ,1870 ,66 ,91 ,16 ,4750 ] flag='' for i in range (len (enc)): if i % 4 ==0 : flag+=chr (enc[i]-i) elif i % 4 ==1 : flag+=chr (enc[i]+i) elif i % 4 ==2 : flag+=chr (enc[i]//i) elif i % 4 ==3 : flag+=chr (enc[i]^i) print (flag)
c:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <stdio.h> void dec (int v2[39 ]) { for (int i = 0 ; i < 39 ; ++i ) { if ( i % 4 ) { switch ( i % 4 ) { case 1 : v2[i] += i; break ; case 2 : v2[i] /= i; break ; case 3 : v2[i] ^= i; break ; } } else { v2[i] -= i; } } } int main () { int enc[39 ]={88 ,88 ,134 ,87 ,74 ,118 ,318 ,101 ,59 ,92 ,480 ,60 ,65 ,41 ,770 ,110 ,73 ,31 ,918 ,39 ,120 ,27 ,1188 ,47 ,77 ,24 ,1352 ,44 ,81 ,23 ,1680 ,46 ,85 ,15 ,1870 ,66 ,91 ,16 ,4750 }; dec(enc); for (int i=0 ;i<39 ;i++){ printf ("%c" ,enc[i]); } return 0 ; }
注意:C 语言的 / 整数除法的效果,Python 用 //
5.XYCTF2024-ez_enc
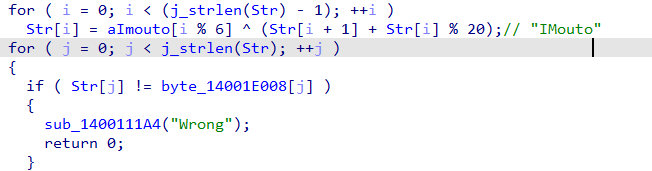
这个就是加密逻辑,Str[i]会依赖Str[i+1],这有点链式效果,这种爆破不好写可以直接使用z3来求解。
密文就是byte_14001E008,直接dump出来就好。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from z3 import *enc = [ 0x27 , 0x24 , 0x17 , 0x0B , 0x50 , 0x03 , 0xC8 , 0x0C , 0x1F , 0x17 , 0x36 , 0x55 , 0xCB , 0x2D , 0xE9 , 0x32 , 0x0E , 0x11 , 0x26 , 0x02 , 0x0C , 0x07 , 0xFC , 0x27 , 0x3D , 0x2D , 0xED , 0x35 , 0x59 , 0xEB , 0x3C , 0x3E , 0xE4 , 0x7D ] key = "IMouto" len = len (enc)Str = [BitVec(f's{i} ' , 8 ) for i in range (len )] s = Solver() for i in range (len ): s.add(Str[i] >= 32 , Str[i] <= 126 ) for i in range (len -1 ): s.add(enc[i] == (ord (key[i % 6 ]) ^ (Str[i+1 ] + (Str[i] % 20 )))) s.add(enc[-1 ] == Str[-1 ]) if s.check() == sat: m = s.model() flag = '' .join([chr (m[Str[i]].as_long()) for i in range (len )]) print ("flag:" , flag) else : print ("unsat" )
6.XYCTF2024-Trustme 使用jeb打开看看MainActivity
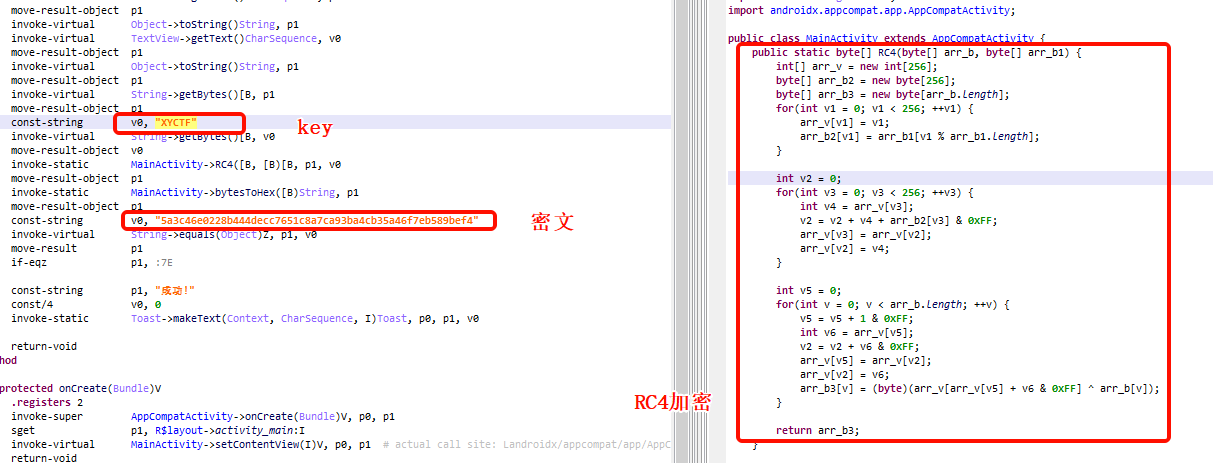
发现这是一个简单的RC4加密,直接进行解密
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def rc4 (data,key ): S = list (range (256 )) j = 0 out = [] for i in range (256 ): j = (j + S[i] +key[i % len (key)]) % 256 S[i],S[j] = S[j],S[i] i=j=0 for c in data: i = (i+1 ) % 256 j = (j+S[i]) % 256 S[i],S[j] = S[j],S[i] K=S[(S[i] + S[j])% 256 ] out.append(c ^ K) return bytes (out) key = b"XYCTF" enc = bytes .fromhex("5a3c46e0228b444decc7651c8a7ca93ba4cb35a46f7eb589bef4" ) decrypted = rc4(enc,key) print ("解密:" , decrypted)print (decrypted.decode())
解出来的并不是flag,而是username 是 admin。这连系一下界面,是要输入用户名和密码的,就是一个登录页面。一般登录页面会使用数据库进行存储内容。
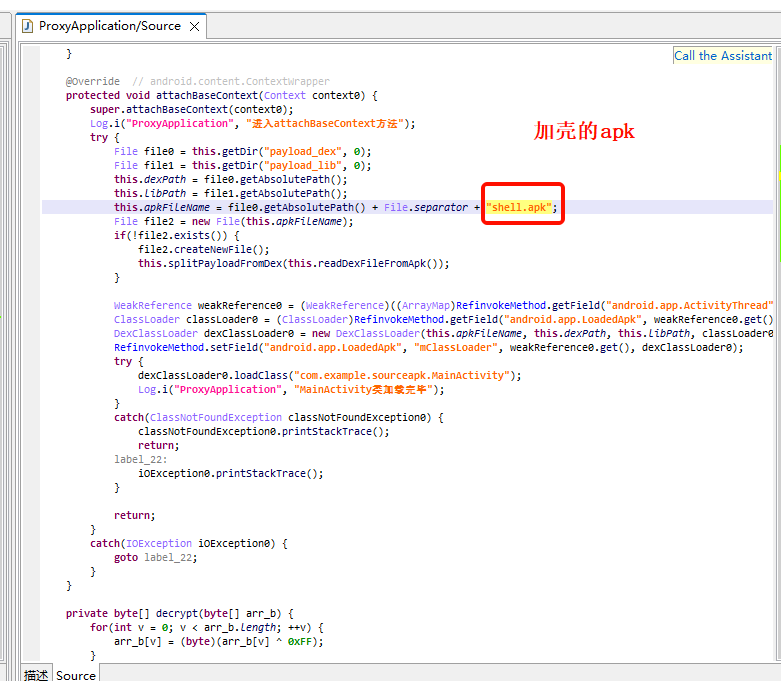
但是还没什么思路,然后找到了一个新的apk
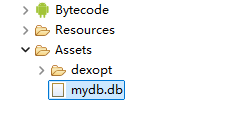
再找找,找到了一个.db文件
在一个 Android APK 里,.db 文件通常就是 SQLite 数据库文件 。它的作用相当于 App 的本地数据库 ,专门用来存储结构化的数据。
.db文件包含了表、索引、视图等数据库对象的定义,以及实际存储的数据。SQLite 是一个自包含的、零配置的、服务器不间断的数据库引擎,不需要单独的服务器进程来管理数据库。这使得它非常适合嵌入式设备或需要简单数据库解决方案的应用程序。
如果使用jadx来导出这个文件会卡死,这里还是使用jeb来导出。
导出后放到010里面查看,发现一大堆0xFF,问了ai才知道,这是未使用的部分保持零填充状态。
在 SQLite 的.db文件中,未存放数据的部分通常会使用零填充。这意味着在文件被创建或者扩展时,未使用的部分会被填充为零字节,这有助于确保文件的完整性并占据磁盘空间以满足文件系统的分配需求。
如果你查看一个.db文件的十六进制表示,你可能会看到一系列的零字节填充,直到遇到存储了数据的部分。SQLite 会在文件中动态分配空间以存储数据,因此未使用的部分会保持零填充状态。
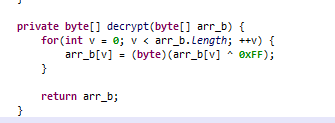
这个是解密的方式
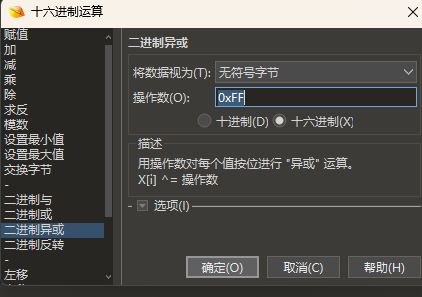
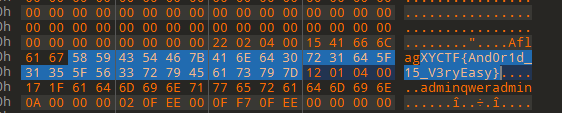
将所有16进制数都异或0xFF。可以直接使用010里面的工具进行异或。
然后在第二段就看到了flag
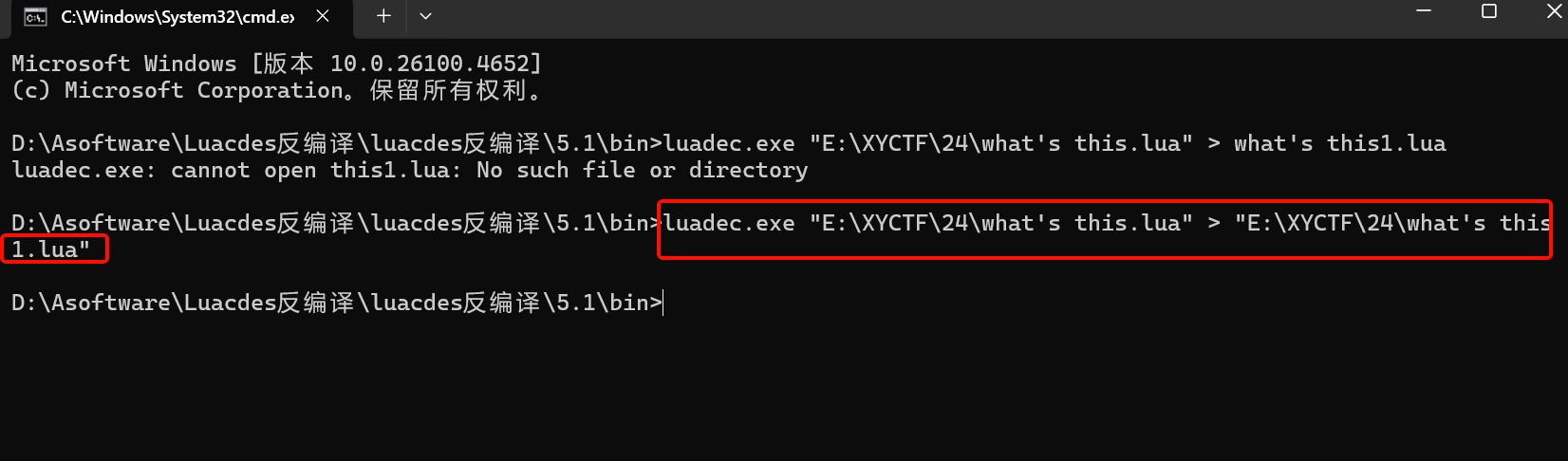
7.XYCTF2024-What’s this 这个没有文件后缀名,先查壳。是我不知道的一种语言,lua。看了师傅的博客才知道,可以去吾爱破解上找到Lua语言的反编译器LuaDec。
https://www.52pojie.cn/thread-1224918-1-1.html
使用方法:luadec.exe 文件名.lua >反编译后的文件名.lua
成功后直接用任意文本编辑器就能打开。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 value = "" output = "" i = 1 while 1 do local temp = (string .byte )(flag, i) temp = (string .char )(Xor(temp, 8 ) % 256 ) value = value .. temp i = i + 1 if (string .len )(flag) < i then break end end do for _ = 1 , 1000 do x = 3 y = x * 3 z = y / 4 w = z - 5 if w == 0 then print ("This line will never be executed" ) end end for i = 1 , (string .len )(flag) do temp = (string .byte )(value, i) temp = (string .char )(temp + 3 ) output = output .. temp end result = output :rep (10 ) invalid_list = {1 , 2 , 3 } for _ = 1 , 20 do (table .insert )(invalid_list, 4 ) end for _ = 1 , 50 do result = result .. "A" ; (table .insert )(invalid_list, 4 ) end for i = 1 , (string .len )(output ) do temp = (string .byte )(output , i) temp = (string .char )(temp - 1 ) end for _ = 1 , 30 do result = result .. (string .lower )(output ) end for _ = 1 , 950 do x = 3 y = x * 3 z = y / 4 w = z - 5 if w == 0 then print ("This line will never be executed" ) end end for _ = 1 , 50 do x = -1 y = x * 4 z = y / 2 w = z - 3 if w == 0 then print ("This line will also never be executed" ) end end require ("base64" ) obfuscated_output = to_base64(output ) obfuscated_output = (string .reverse )(obfuscated_output) obfuscated_output = (string .gsub )(obfuscated_output, "g" , "3" ) obfuscated_output = (string .gsub )(obfuscated_output, "H" , "4" ) obfuscated_output = (string .gsub )(obfuscated_output, "W" , "6" ) invalid_variable = obfuscated_output:rep (5 ) if obfuscated_output == "==AeuFEcwxGPuJ0PBNzbC16ctFnPB5DPzI0bwx6bu9GQ2F1XOR1U" then print ("You get the flag." ) else print ("F**k!" ) end end
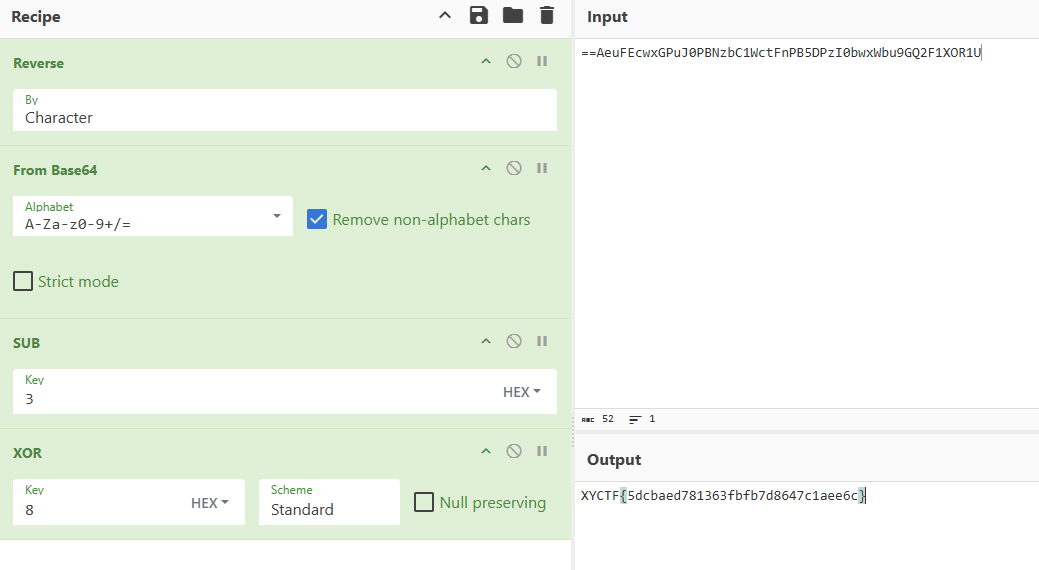
处理过程是:先将字符串与8异或,再每个字节+3,然后base64加密,再翻转,最后进行替换。这样出来的密文要与”==AeuFEcwxGPuJ0PBNzbC16ctFnPB5DPzI0bwx6bu9GQ2F1XOR1U”一致,才正确。
这里已经最后一步进行了,只有6,说明只用替换6为W。
替换后的结果:**==AeuFEcwxGPuJ0PBNzbC1WctFnPB5DPzI0bwxWbu9GQ2F1XOR1U**
直接使用CyberChef一把唆
8.XYCTF24-舔狗四部曲–相逢已是上上签 听说你PE,工具,算法都学的很好尊嘟假嘟?
PE这部分知识我还不太熟悉,找个大佬的博客立马开始学!
https://thunderjie.github.io/2019/03/27/PE%E7%BB%93%E6%9E%84%E8%AF%A6%E8%A7%A3/
PE文件的基本结构: 1.DOS 部分 DOS部分主要是为了兼容以前的DOS系统,DOS部分可以分为DOS MZ文件头(IMAGE_DOS_HEADER)和DOS块(DOS Stub)。
其中重要的是e_magic成员和e_lfanew成员。e_magic就是魔数,文件开头两个字节MZ(0x4D,0x5A),e_lfanew是指向 PE Header 的文件偏移地址。一般在第四排四个字节指向的地址会指向真正的 PE 头(50 45)。这两个条件满足,就是一个有效的PE文件。
DOS块的部分就是PE文件头和DOS MZ文件头中间的部分。这部分是由链接器所写入的,可以随意进行修改,并不影响程序的运行。
2.PE文件头 PE文件头由PE文件头标志,标准PE头,扩展PE头三部分组成。PE文件头标志自然是50 40 00 00,也就是PE。
PE文件头的详细信息:
1 2 3 4 5 typedef struct _IMAGE_NT_HEADERS { DWORD Signature; IMAGE_FILE_HEADER FileHeader; IMAGE_OPTIONAL_HEADER32 OptionalHeader; } IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
标准PE头结构:
1 2 3 4 5 6 7 8 9 typedef struct _IMAGE_FILE_HEADER { WORD Machine; WORD NumberOfSections; DWORD TimeDateStamp; DWORD PointerToSymbolTable; DWORD NumberOfSymbols; WORD SizeOfOptionalHeader; WORD Characteristics; } IMAGE_FILE_HEADER;
扩展 PE 头结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 typedef struct _IMAGE_OPTIONAL_HEADER32 { WORD Magic; BYTE MajorLinkerVersion; BYTE MinorLinkerVersion; DWORD SizeOfCode; DWORD SizeOfInitializedData; DWORD SizeOfUninitializedData; DWORD AddressOfEntryPoint; DWORD BaseOfCode; DWORD BaseOfData; DWORD ImageBase; DWORD SectionAlignment; DWORD FileAlignment; WORD MajorOperatingSystemVersion; WORD MinorOperatingSystemVersion; WORD MajorImageVersion; WORD MinorImageVersion; WORD MajorSubsystemVersion; WORD MinorSubsystemVersion; DWORD Win32VersionValue; DWORD SizeOfImage; DWORD SizeOfHeaders; DWORD CheckSum; WORD Subsystem; WORD DllCharacteristics; DWORD SizeOfStackReserve; DWORD SizeOfStackCommit; DWORD SizeOfHeapReserve; DWORD SizeOfHeapCommit; DWORD LoaderFlags; DWORD NumberOfRvaAndSizes; IMAGE_DATA_DIRECTORY DataDirectory[16 ]; } IMAGE_OPTIONAL_HEADER32;
程序的真正入口点 = ImageBase + AddressOfEntryPoint
ImageBase → 默认加载基址(x86 默认 0x400000,x64 默认 0x140000000)。
AddressOfEntryPoint 就是程序入口点(相对虚拟地址,RVA)。
3.节表 节表位于PE头之后,它是一个数组,每个元素对应一个节的描述信息,决定了程序的代码块,数据段等在内存和文件中的布局。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 typedef struct _IMAGE_SECTION_HEADER { BYTE Name[8 ]; union { DWORD PhysicalAddress; DWORD VirtualSize; } Misc; DWORD VirtualAddress; DWORD SizeOfRawData; DWORD PointerToRawData; DWORD PointerToRelocations; DWORD PointerToLinenumbers; WORD NumberOfRelocations; WORD NumberOfLinenumbers; DWORD Characteristics; } IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
4.导入表 描述程序要从其他DLL导入的函数
导入表的核心结构定义在 WinNT.h ,主要用到以下结构:
1.IMAGE_IMPORT_DESCRIPTOR (20字节)
1 2 3 4 5 6 7 8 9 10 11 typedef struct _IMAGE_IMPORT_DESCRIPTOR { union { DWORD Characteristics; DWORD OriginalFirstThunk; }; DWORD TimeDateStamp; DWORD ForwarderChain; DWORD Name; DWORD FirstThunk; } IMAGE_IMPORT_DESCRIPTOR;
OriginalFirstThunk → 指向导入名称表(INT),记录要导入的函数名或序号。
FirstThunk → 指向导入地址表(IAT),程序运行时会被填充为实际的函数地址。
2.导入名称表(INT)和导入地址表(IAT)
每个表项都是一个 IMAGE_THUNK_DATA 结构(32位或64位不同):
1 2 3 4 5 6 7 8 typedef struct _IMAGE_THUNK_DATA32 { union { DWORD ForwarderString; DWORD Function; DWORD Ordinal; DWORD AddressOfData; }; } IMAGE_THUNK_DATA32;
如果 HighestBit = 1,说明是按 序号导入 ;否则是按 函数名导入 。
3.IMAGE_IMPORT_BY_NAME
当按函数名导入时,AddressOfData 指向这个结构:
1 2 3 4 typedef struct _IMAGE_IMPORT_BY_NAME { WORD Hint; CHAR Name[1 ]; } IMAGE_IMPORT_BY_NAME;
流程:遍历 IMAGE_IMPORT_DESCRIPTOR → 找到 DLL 名称。
遍历 INT → 找到函数名或序号。
加载 DLL,并把函数实际地址写入 IAT。
程序调用时直接用 IAT 里的地址
5.导出表 程序提供给外部调用的函数,
IMAGE_EXPORT_DIRECTORY (40字节)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 typedef struct _IMAGE_EXPORT_DIRECTORY { DWORD Characteristics; DWORD TimeDateStamp; WORD MajorVersion; WORD MinorVersion; DWORD Name; DWORD Base; DWORD NumberOfFunctions; DWORD NumberOfNames; DWORD AddressOfFunctions; DWORD AddressOfNames; DWORD AddressOfNameOrdinals; } IMAGE_EXPORT_DIRECTORY;
AddressOfFunctions 是函数地址表,指向每个函数真正的地址,AddressOfNames 和 AddressOfNameOrdinals 分别是函数名称表和函数序号表,我们知道DLL文件有两种调用方式,一种是用名字,一种是用序号,通过这两个表可以用来寻找函数在 AddressOfFunctions 表中真正的地址。
6.重定位表 当PE文件被装载到虚拟内存的另一个地址中的时候,也就是载入时不将默认的值作为基地址载入,链接器登记的哪个地址是错误的,需要我们用重定位表来调整,重定位表在数据目录项的第 6 个结构,结构如下
1 2 3 4 5 6 typedef struct _IMAGE_BASE_RELOCATION { DWORD VirtualAddress; DWORD SizeOfBlock; } IMAGE_BASE_RELOCATION; typedef IMAGE_BASE_RELOCATION UNALIGNED * PIMAGE_BASE_RELOCATION;
重定位表有许多个,以八个字节的 0 结尾
ok大致了解后,回到这道题。
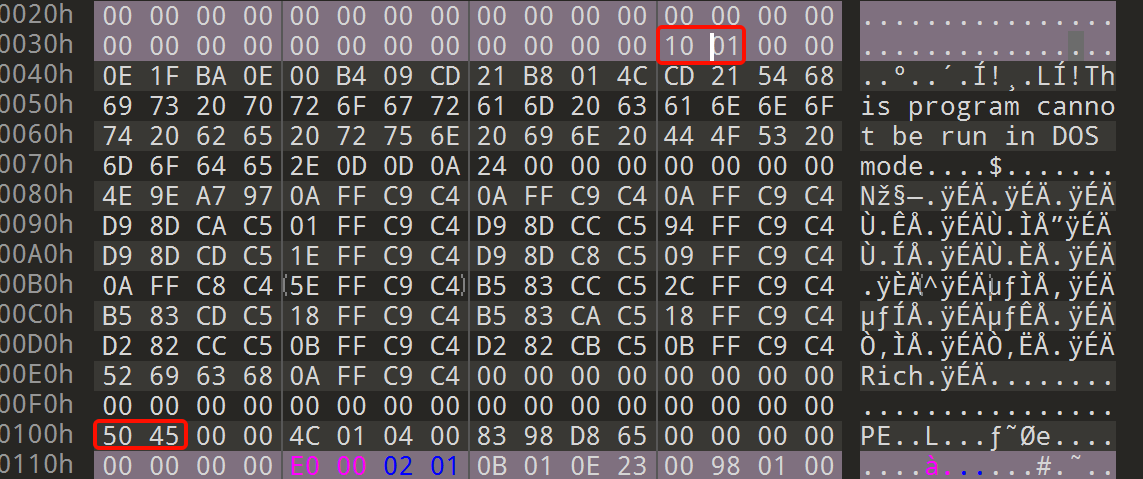
使用010打开进行查看
这个e_lfanew指向的偏移地址是错误的,我们能看到 50 45在100h的地方,这里 10 01 00 00 是小端序 ,其值是0x00000110,所以这个偏移错误的指向了0x110,而不是0x100。想要正确指向0x100,就要改成 00 01 00 00
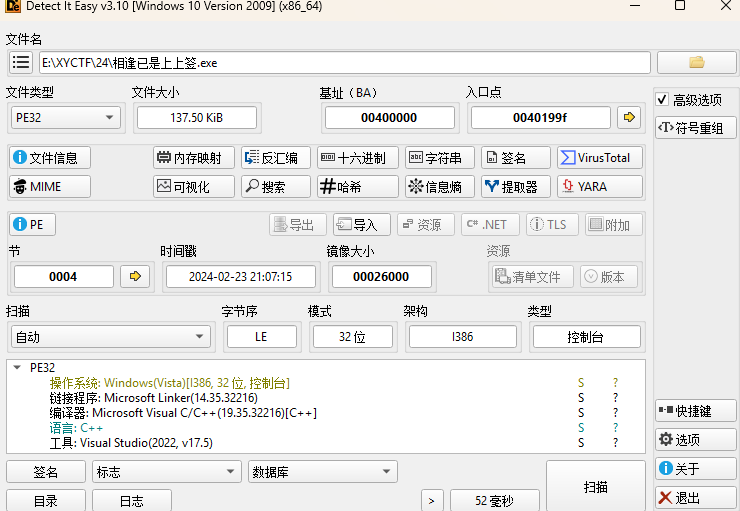
将其修改后保存,再进行查壳。就能识别出来PE文件了。
然后放到ida里面进行逆向分析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 from z3 import *byte_422918 = [BitVec(f"char_{i} " , 32 ) for i in range (6 )] s=Solver() s.add( 532 *(byte_422918[5 ]) + 829 *(byte_422918[4 ]) + 258 *(byte_422918[3 ]) + 811 *(byte_422918[2 ]) + 997 *(byte_422918[1 ]) + 593 * byte_422918[0 ] == 292512 ) s.add( 576 *(byte_422918[5 ]) + 695 *(byte_422918[4 ]) + 602 *(byte_422918[3 ]) + 328 * (byte_422918[2 ]) + 686 * (byte_422918[1 ]) + 605 * byte_422918[0 ] == 254496 ) s.add( 580 * (byte_422918[5 ]) + 448 * (byte_422918[4 ]) + 756 * (byte_422918[3 ]) + 449 * (byte_422918[2 ]) + ((byte_422918[1 ]) << 9 ) + 373 * byte_422918[0 ] == 222479 ) s.add( 597 * (byte_422918[5 ]) + 855 * (byte_422918[4 ]) + 971 * (byte_422918[3 ]) + 422 * (byte_422918[2 ]) + 635 * (byte_422918[1 ]) + 560 * byte_422918[0 ] == 295184 ) s.add( 524 * (byte_422918[5 ]) + 324 * (byte_422918[4 ]) + 925 * (byte_422918[3 ]) + 388 * (byte_422918[2 ]) + 507 * (byte_422918[1 ]) + 717 * byte_422918[0 ] == 251887 ) s.add( 414 * (byte_422918[5 ]) + 495 * (byte_422918[4 ]) + 518 * (byte_422918[3 ]) + 884 * (byte_422918[2 ]) + 368 * (byte_422918[1 ]) + 312 * byte_422918[0 ] == 211260 ) s.check() print (s.model())key=[88 ,89 ,67 ,84 ,70 ,33 ] key1='' for i in range (len (key)): key1+=chr (key[i]) print (key1)
密钥是XYCTF!
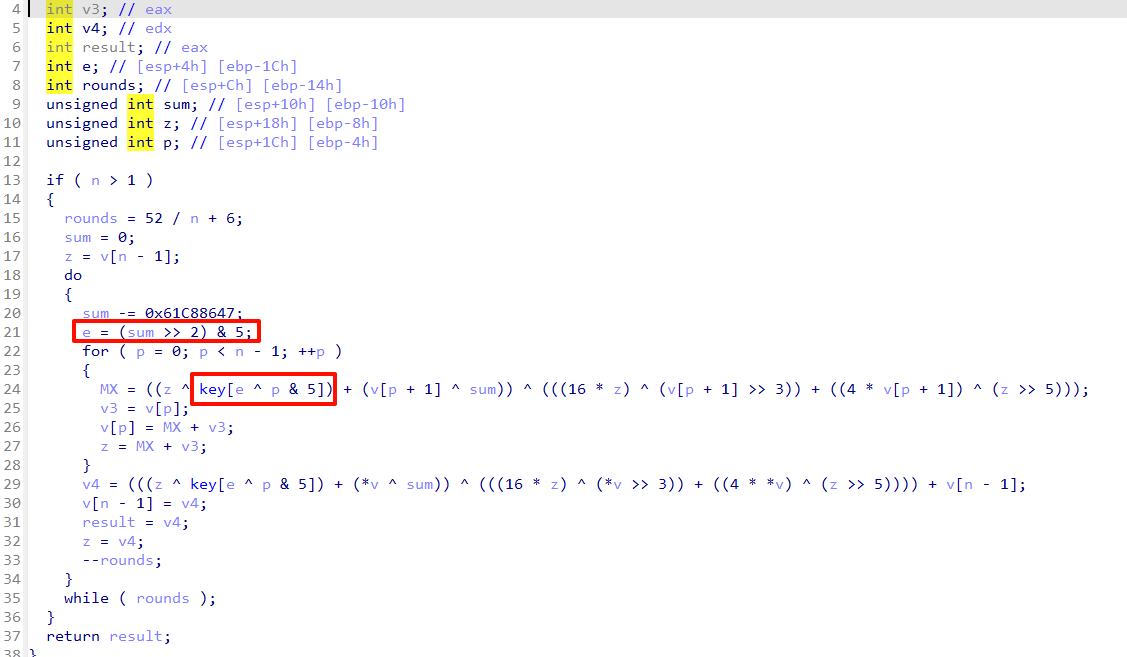
然后使用IDA打开,就是xxtea
这个**-0x61c88647=0×9E3779B9**,主要变的地方就是上面的圈起的部分
写出脚本解密
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 #define DELTA 0x9E3779B9 #define MX (((z>>5^y<<2) + (y> >3^z<<4)) ^ ((sum^y) + (key[(p&5)^e] ^ z))) #include <stdio.h> #include <stdint.h> void xxtea (uint32_t * v, int n, uint32_t const *key) { uint32_t y, z, sum; unsigned p, rounds, e; if (n > 1 ) { rounds = 6 + 52 / n; sum = 0 ; z = v[n - 1 ]; do { sum += DELTA; e = (sum >> 2 ) & 5 ; for (p = 0 ; p < n - 1 ; p++) { y = v[p + 1 ]; z = v[p] += MX; } y = v[0 ]; z = v[n - 1 ] += MX; } while (--rounds); } else if (n < -1 ) { n = -n; rounds = 6 + 52 / n; sum = rounds * DELTA; y = v[0 ]; do { e = (sum >> 2 ) & 5 ; for (p = n - 1 ; p > 0 ; p--) { z = v[p - 1 ]; y = v[p] -= MX; } z = v[n - 1 ]; y = v[0 ] -= MX; sum -= DELTA; } while (--rounds); } } int main () { uint32_t v[8 ] = {0x66697271 , 0x896E2285 , 0xC5188C1B , 0x72BCFD03 , 0x538011CA , 0x4DA146AC , 0x86630D6B , 0xF89797F0 }; uint32_t k[6 ] = {0x58 ,0x59 ,0x43 ,0x54 ,0x46 ,0x21 }; int n = 8 ; printf ("Data is :%x %x\n" ,v[0 ],v[1 ]); xxtea(v, -n, k); printf ("Decrypted data: " ); for (int i = 0 ; i < n; ++i) printf ("%08x\n " , v[i]); for (int i = 0 ; i < n; i++) { for (int j = 0 ; j <sizeof (uint32_t ) / sizeof (uint8_t ) ; j++) { printf ("%c" , (v[i] >> (j * 8 )) & 0xFF ); } } printf ("\n" ); }
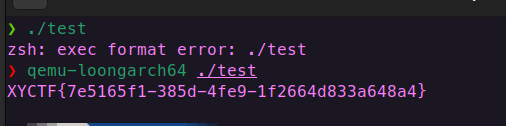
9.XYCTF24-今夕是何年 都是兄弟,真的运行就出flag了😋
把这个附件放到Ubuntu里面,使用file ./文件名 来查看架构信息
LoongArch(龙架构,全称 Loongson Architecture )是中国龙芯中科 在 2021 年发布的一种自主指令集架构 。
但是并没有这个架构,方法是安装qemu ,它可以跨架构来跑程序。