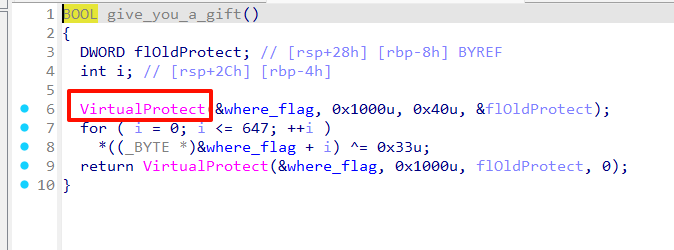
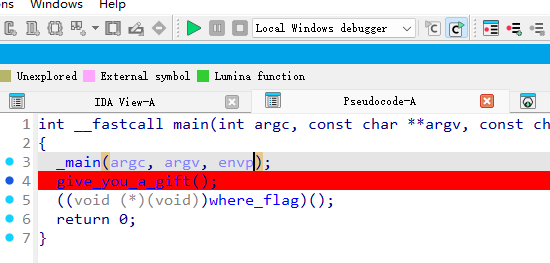
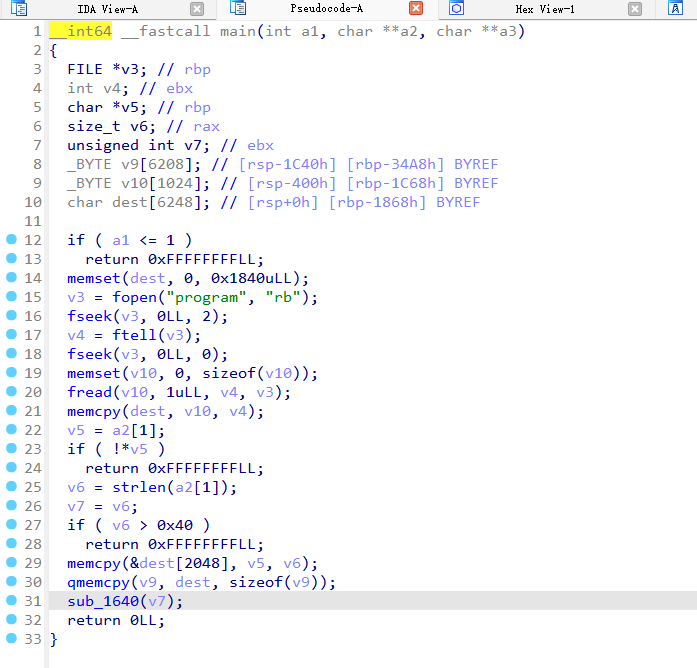
25年浙江省决赛re复现 re1.你是我的天命人吗 先查壳,无壳直接IDA启动!在main函数里看到两个函数,一个是give_you_a_gift(),另一个是 where_flag 。
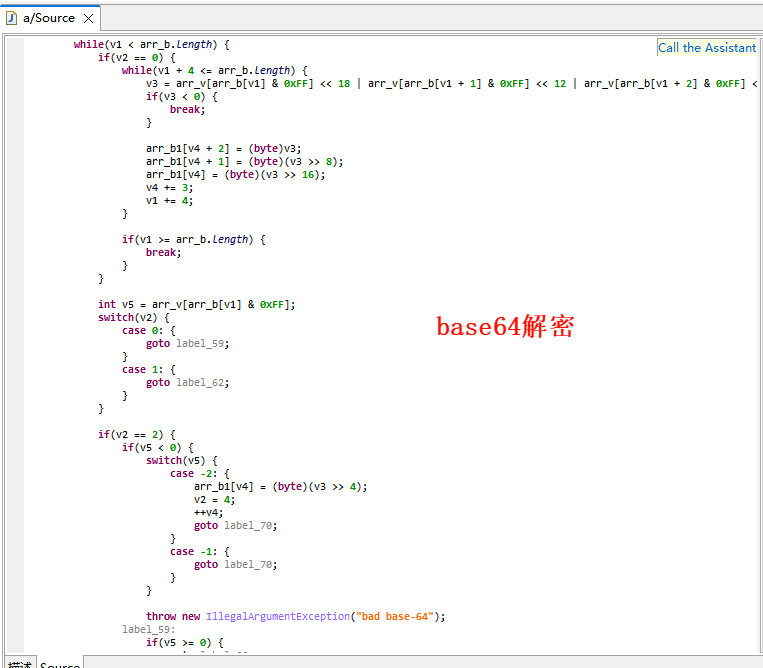
第一个函数里是VirtualProtect,这是代码自解密。解密的长度是648,开始位置就是where_flag,解密方式是逐字节异或0x33。
1.可以使用idapython,写脚本解密
1 2 3 4 5 6 7 8 start = 0x1400018C5 length = 648 for i in range (length): b = ida_bytes.get_byte(start + i) ida_bytes.patch_byte(start + i, b ^ 0x33 ) print ("Decrypt done." )
2.可以动态调试,让程序自己运行到where_flag函数处,进行解密。
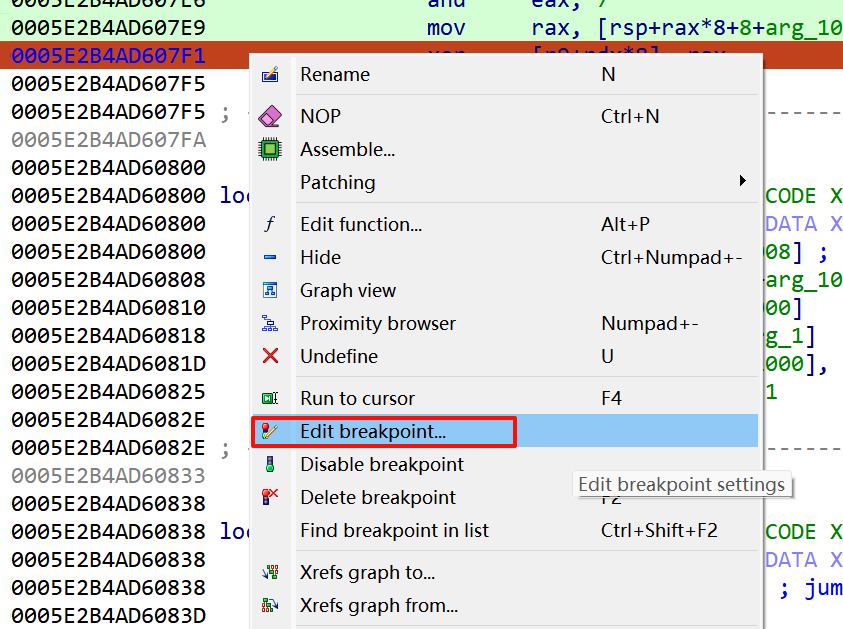
在give_you_a_gift()处打上断点,然后F9运行
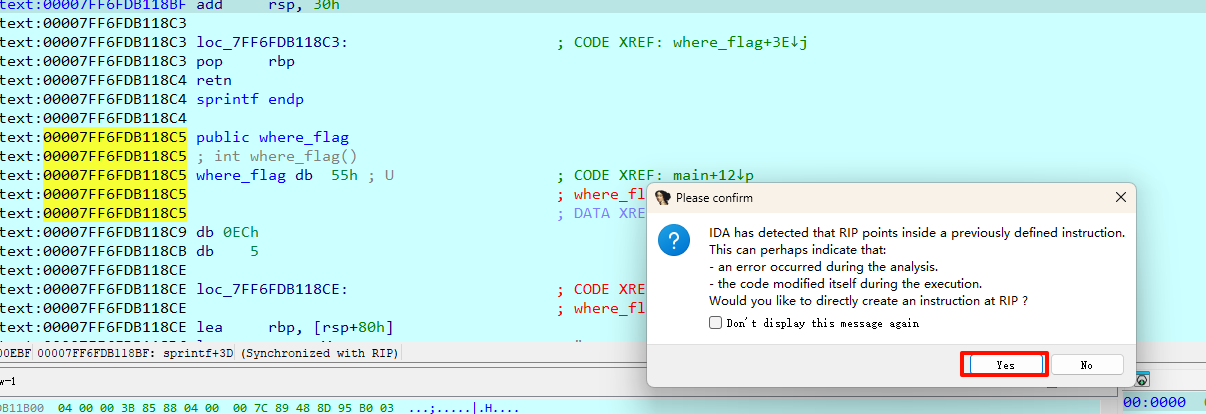
然后F7进入where_flag函数,看到出来了一个弹窗,这个弹窗的意思是 要不要从当前 RIP 开始,把这里重新当成一条新的指令来反汇编?直接点击yes,让ida重新分析就好。
选中这个函数先按U解除定义,再在where_flag函数头按P重新定义一下就行
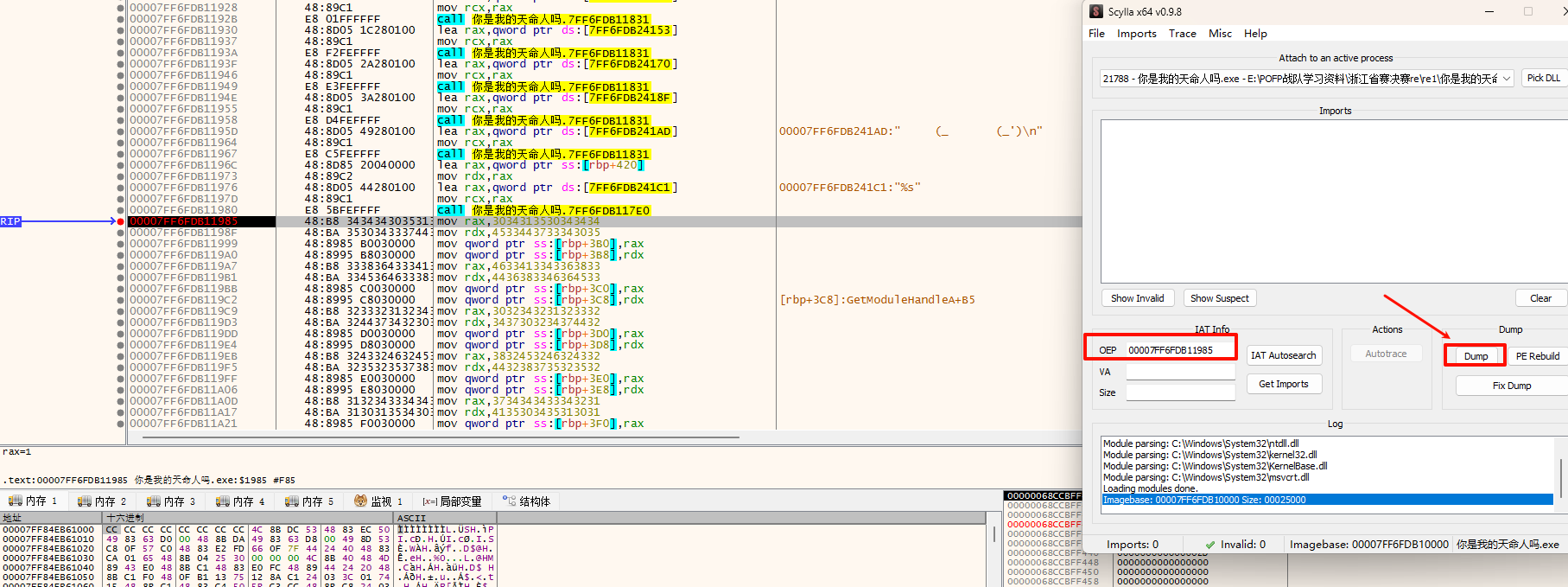
3.也可以使用x64dbg去dump
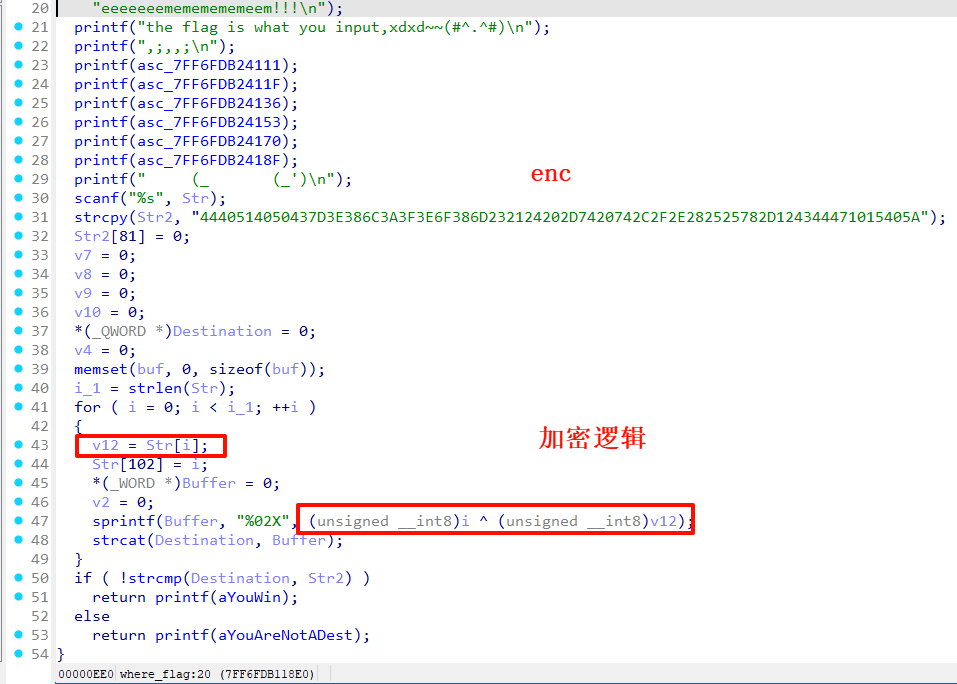
dump后可以看到主要逻辑
就是简单的异或,逆向过来就是enc的索引值与enc的值异或
写出解密脚本
这里本人太无知了,python有一个内置库binascii,
功能:做二进制数据 和各种文本表示形式 之间的转换,比如:
十六进制字符串 → 原始字节 binascii.unhexlify()
原始字节 → 十六进制字符串 binascii.hexlify()
二进制 -> base64 形式 binascii.b2a_base64
base64 -> 二进制 binascii.a2b_base64
CRC 校验 binascii.crc32(data)
1 2 3 4 5 6 7 import binasciienc=bytearray (binascii.unhexlify('4440514050437D3E386C3A3F3E6F386D232124202D7420742C2F2E282525782D124344471015405A' )) print (enc)flag='' for i in range (len (enc)): flag+=chr (enc[i]^i) print (flag)
另一种:
1 2 3 4 5 6 7 enc=bytes .fromhex('4440514050437D3E386C3A3F3E6F386D232124202D7420742C2F2E282525782D124344471015405A' ) print (enc)flag='' for i in range (len (enc)): flag+=chr (enc[i]^i) print (flag)
re2.androidtest.apk 使用jeb打开,找到MainActivity进行分析
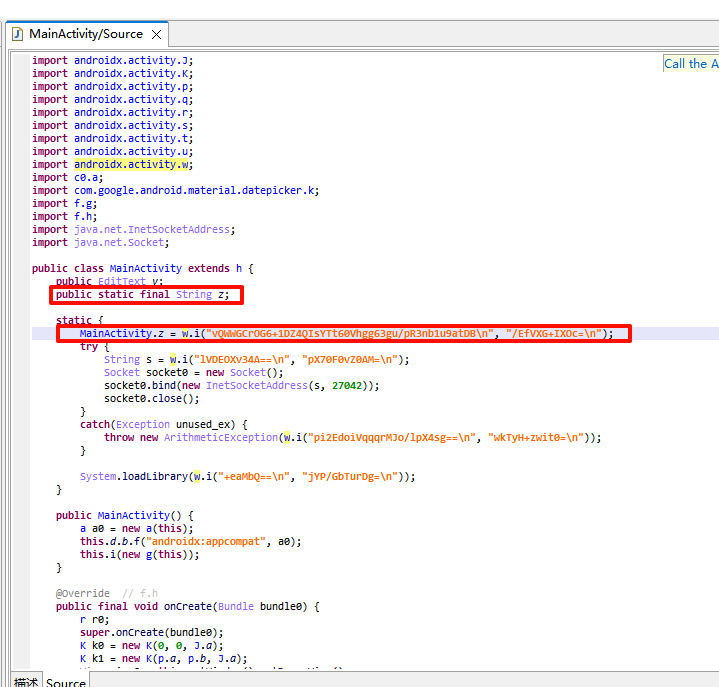
可以看到字符串z是一个静态常量,下面是对字符串z的实现,通过 w.i() 方法来对类似base64的字符串进行一些解密操作。
直接对import androidx.activity.w; 这个类右键交叉引用,找到w类,查找i方法
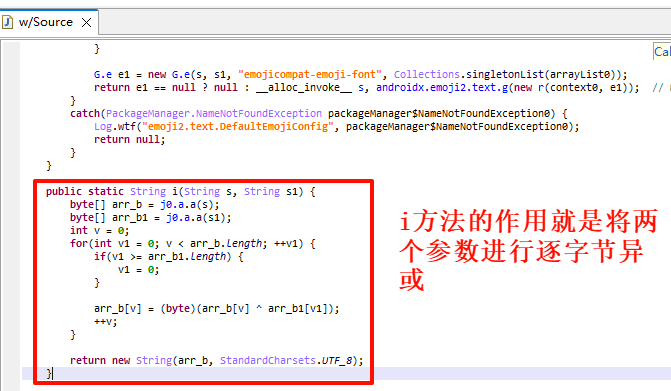
看到i方法里还调用了j0.a.a方法,直接点进去,发现这是实现了一个base64解码器
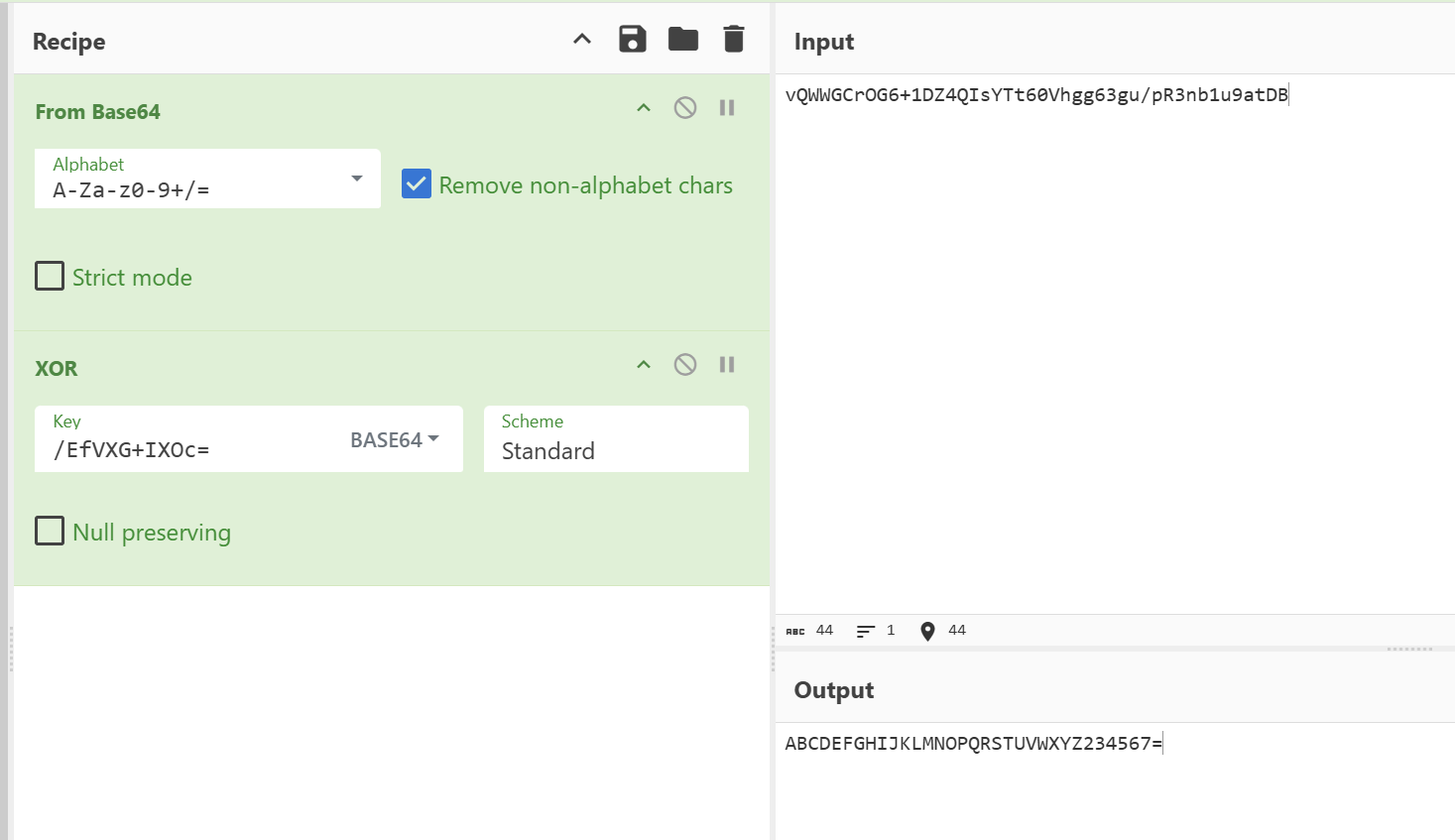
那么这些方法的作用都清楚了,就是对那两个字符串先base64解码,然后将后位的字符串作为密钥去异或前位的字符串,这样就可以解出来字符串z。
这个字符串是base32的字母表(其实这里还看不出来什么)
接着往下分析MainActivity
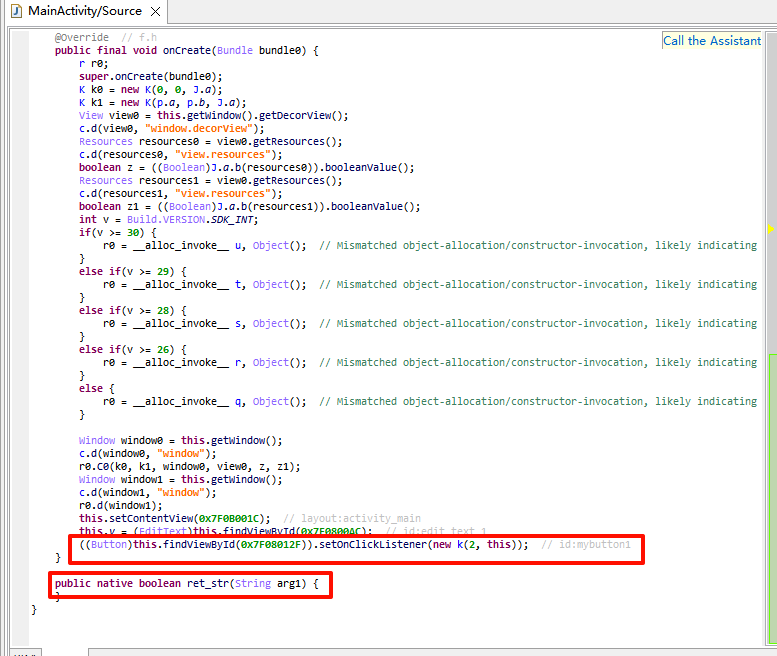
这里可以看到ret_str(String arg1)函数是一个 JNI 函数 ,在 libtest.so 中实现,直接右键解析出来,放到ida里面进行查看
这里只有一个字符串,它看起来像base系列的密文,接着再进行分析。
对**ret_str(String arg1)**函数进行交叉引用,来到了k类,具体代码如下所示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 package com.google.android.material.datepicker;import android.view.View.OnClickListener;import android.view.View;import android.widget.Toast;import androidx.activity.w;import androidx.appcompat.widget.Toolbar;import com.example.myapplication.MainActivity;import f.e;import i.b;import j.o;import k.Y0;public final class k implements View .OnClickListener { public final int a; public final Object b; public k (int v, Object object0) { this .a = v; this .b = object0; super (); } @Override public final void onClick (View view0) { String s3; String s2; int v6; String s1; switch (this .a) { case 0 : { l l0 = (l)this .b; int v = l0.X; if (v == 2 ) { l0.H(1 ); return ; } if (v == 1 ) { l0.H(2 ); } return ; } case 1 : { ((e)this .b).w.obtainMessage(1 , ((e)this .b).b).sendToTarget(); return ; } case 2 : { MainActivity mainActivity0 = (MainActivity)this .b; String s = mainActivity0.y.getText().toString(); if (s.length() == 44 ) { int v1 = (byte )s.length(); byte [] arr_b = s.getBytes(); byte [] arr_b1 = new byte [arr_b.length]; for (int v3 = 0 ; v3 < arr_b.length; ++v3) { arr_b1[v3] = (byte )(arr_b[v3] ^ v1); } StringBuilder stringBuilder0 = new StringBuilder (); int v4 = 0 ; int v5 = 0 ; for (int v2 = 0 ; true ; ++v2) { s1 = MainActivity.z; if (v2 >= arr_b.length) { break ; } v5 = v5 << 8 | arr_b1[v2] & 0xFF ; v4 += 8 ; while (v4 >= 5 ) { stringBuilder0.append(s1.charAt(v5 >>> v4 - 5 & 0x1F )); v4 += -5 ; } } if (v4 > 0 ) { v6 = s1.charAt(v5 << 5 - v4 & 0x1F ); stringBuilder0.append(((char )v6)); } label_44: if (stringBuilder0.length() % 8 != 0 ) { v6 = 61 ; stringBuilder0.append(((char )v6)); goto label_44; } if (mainActivity0.ret_str(stringBuilder0.toString())) { s2 = "7F+v030i4Hk=\n" ; s3 = "vyrMsBhRk1g=\n" ; } else { s2 = "mrVcl8J8\n" ; s3 = "/8cu+LBdMiY=\n" ; } Toast.makeText(mainActivity0, w.i(s2, s3), 1 ).show(); return ; } throw new ArithmeticException (w.i("4nC+/ChD4PbvbaC1NkOy7g==\n" , "hhnIlUwmwIE=\n" )); } case 3 : { ((b)this .b).a(); return ; } default : { Y0 y00 = ((Toolbar)this .b).L; o o0 = y00 == null ? null : y00.b; if (o0 != null ) { o0.collapseActionView(); } return ; } } } }
OnClickListener ,被复用在好几个地方,在构造函数里传了一个 int a 指示“这是第几种用法”。switch(this.a) 根据不同的值执行不同逻辑。
再联系一下MainActivity的 ((Button)this.findViewById(0x7F08012F)).setOnClickListener(new k(2, this)); // id:mybutton1 。
这里传参是2,意味着加密逻辑是调用的case2,接着细看case2的逻辑:
就是先判断一下传入的字符串长度是不是44,如果是44的话,就让字符串逐字节与44进行异或,异或后进行base32加密,最后与ret_str传入的字符串进行对比验证。
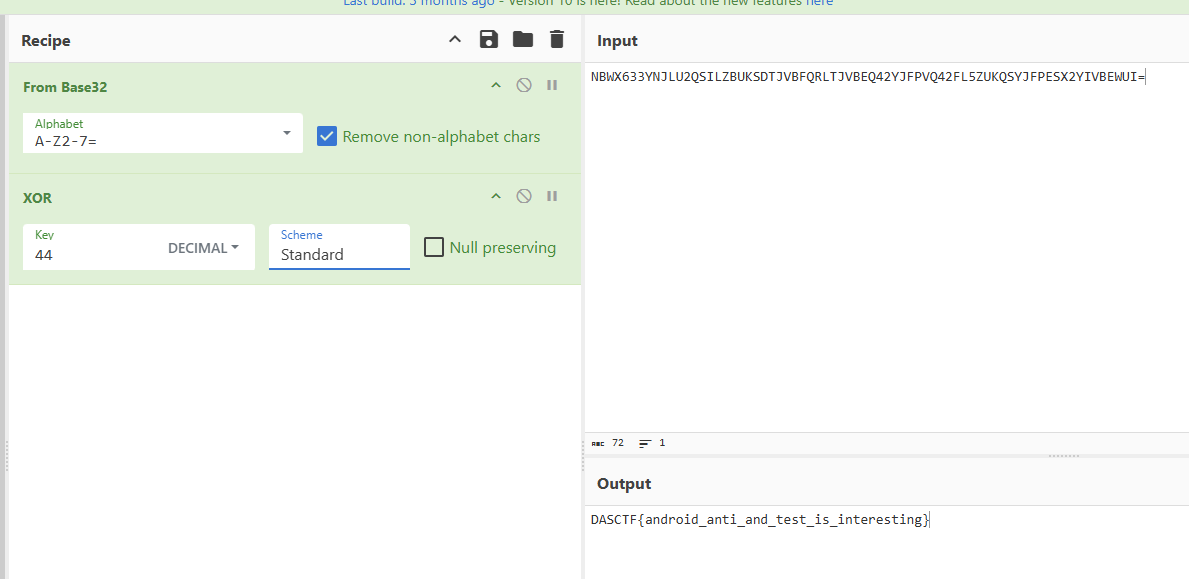
逆向思路就是将”NBWX633YNJLU2QSILZBUKSDTJVBFQRLTJVBEQ42YJFPVQ42FL5ZUKQSYJFPESX2YIVBEWUI=”字符串先base32解密,再xor 44
或者写脚本
1 2 3 4 5 6 import base64a = list (base64.b32decode('NBWX633YNJLU2QSILZBUKSDTJVBFQRLTJVBEQ42YJFPVQ42FL5ZUKQSYJFPESX2YIVBEWUI=' )) for i in a: print (chr (i ^ 44 ), end='' )
re3 vm 本题有两个附件,一个是program,一个是Wraning,ELF文件。对它查壳,无壳64位,依旧IDA启动。
找到main函数进行分析
在解题前先补充一个知识点,就是命令行参数
在 C 里,main 的这三个参数通常是:
1 int main (int argc, char **argv, char **envp)
a1 对应 argc 命令行参数的个数,最少是1,argv[0] 永远是程序本身的路径(比如本题 ./wraning)。a2 对应 argv 命令行参数字符串数组,argv 是一个“指针数组”,每个元素是一个 char *,指向一个以 \0 结尾的 C 字符串。a3 对应 envp 环境变量字符串数组,跟 argv 类似,也是“字符串指针数组”,不过内容是环境变量。
对应main函数中
1 2 if ( a1 <= 1 ) return 0xFFFFFFFF LL;
a1 <= 1 等价于 “命令行参数个数小于等于 1”,如果没有额外的命令行参数,就会返回0xFFFFFFFFLL,也就是 -1,作为进程退出码,通常会表现为退出码 255(取低 8 位)。
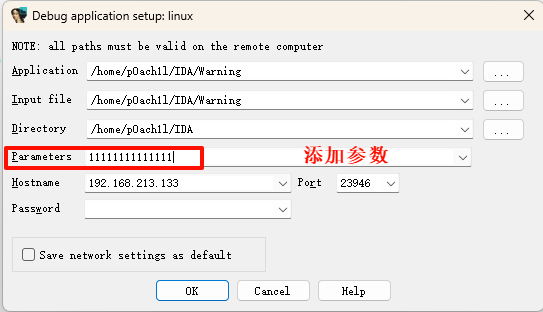
动态调试时,调试器启动程序时,相当于在命令行只执行了: ./program
这时 argc == 1,也就是 a1 == 1,所以要再额外输入参数
1 2 3 v5 = a2[1 ]; if ( !*v5 ) return 0xFFFFFFFF LL;
取命令行参数 argv[1],如果第一个字符就是 ‘\0’,即空字符串就退出。
1 2 3 4 v6 = strlen (a2[1 ]); v7 = v6; if ( v6 > 0x40 ) return 0xFFFFFFFF LL;
获取 argv[1] 的长度,限制长度最长是 0x40 = 64 字节,超过就会退出。
大概逻辑是这样的,它还会读取文件program的内容到v10,并把文件内容复制到 dest 开头,然后把传入的参数字符串放到 dest + 2048 的位置,接着把这个大缓冲区复制到 v9,然后把参数长度传给 sub_1640 做进一步处理。
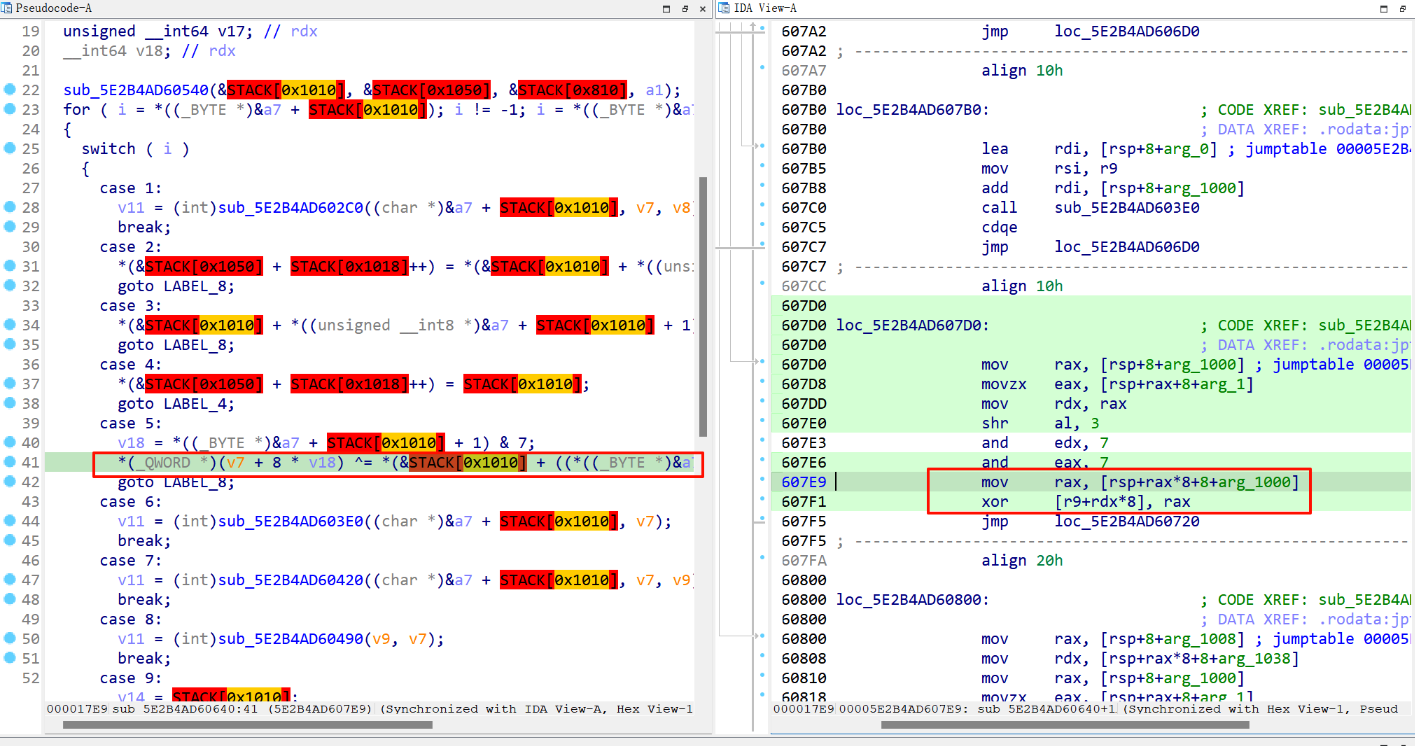
接着分析sub_1640函数,这有好多case,一眼vm,一般方法是分析每个opcode的作用,自己写一个解释器,但这有些耗费时间和精力,霍雅师傅闪亮登场,教我本题可以使用trace来看。记录一下hhh🤗
做法:1.先静态分析一下,看大致的opcode的作用
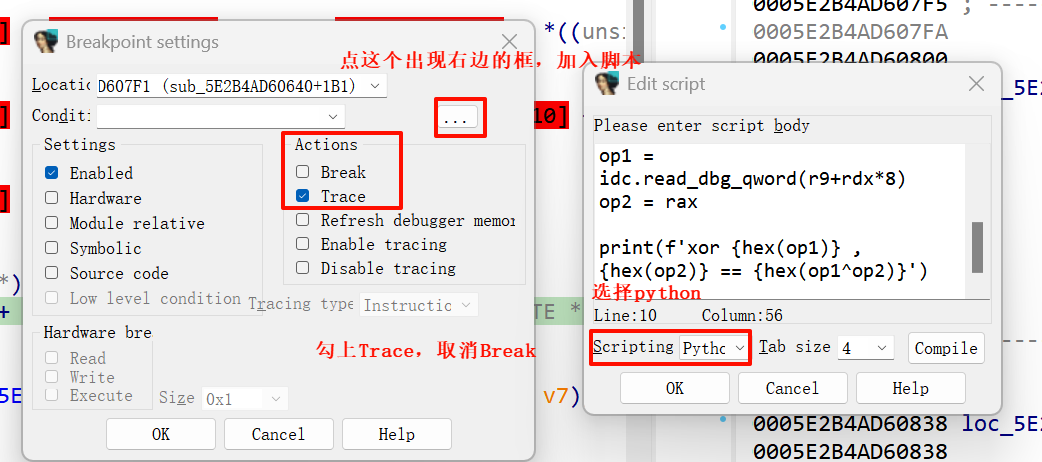
2.在关键指令(进行一些异或,左移,右移之类的)上打断点
3.写出对应的idc脚本,在 VM 的“取指/dispatch”位置做循环 trace ,每步记录 opcode、寄存器、内存变化
对应的idc脚本
1 2 3 4 5 6 7 8 9 10 import idcr9 = idc.get_reg_value('r9' ) rdx = idc.get_reg_value('rdx' ) rax = idc.get_reg_value('rax' ) op1 = idc.read_dbg_qword(r9+rdx*8 ) op2 = rax print (f'xor {hex (op1)} , {hex (op2)} == {hex (op1^op2)} ' )
在汇编视图下的xor处打上断点,右键选择Edit breakpoint settings
然后把脚本粘贴上去
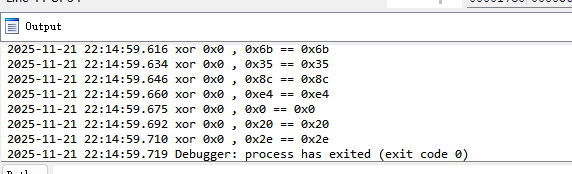
然后动态调试,循环结束后,就会退出,并在output窗口打印出 寄存器所做的操作
如下所示
小技巧 :复制在vscode里面可以使用列块选择来一次性截取同一纵向位置的内容,Shift + Alt 按住,再用鼠标左键拖出一个“竖长的矩形”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 xor 0x31 , 0x0 == 0x31 xor 0x31 , 0x1 == 0x30 xor 0x31 , 0x2 == 0x33 xor 0x31 , 0x3 == 0x32 xor 0x31 , 0x4 == 0x35 xor 0x31 , 0x5 == 0x34 xor 0x31 , 0x6 == 0x37 xor 0x31 , 0x7 == 0x36 xor 0x31 , 0x8 == 0x39 xor 0x31 , 0x9 == 0x38 xor 0x31 , 0xa == 0x3b xor 0x31 , 0xb == 0x3a xor 0x31 , 0xc == 0x3d xor 0x31 , 0xd == 0x3c xor 0x31 , 0x50 == 0x61 xor 0x30 , 0x67 == 0x57 xor 0x33 , 0x21 == 0x12 xor 0x32 , 0x2b == 0x19 xor 0x35 , 0xce == 0xfb xor 0x34 , 0xd7 == 0xe3 xor 0x37 , 0x84 == 0xb3 xor 0x36 , 0x3a == 0xc xor 0x39 , 0xf5 == 0xcc xor 0x38 , 0xc2 == 0xfa xor 0x3b , 0xc2 == 0xf9 xor 0x3a , 0x22 == 0x18 xor 0x3d , 0x48 == 0x75 xor 0x3c , 0x1d == 0x21 xor 0x0 , 0x14 == 0x14 xor 0x0 , 0x2a == 0x2a xor 0x0 , 0x71 == 0x71 xor 0x0 , 0x25 == 0x25 xor 0x0 , 0xa7 == 0xa7 xor 0x0 , 0x73 == 0x73 xor 0x0 , 0x3c == 0x3c xor 0x0 , 0x9c == 0x9c xor 0x0 , 0x72 == 0x72 xor 0x0 , 0xfe == 0xfe xor 0x0 , 0x3c == 0x3c xor 0x0 , 0xb7 == 0xb7 xor 0x0 , 0xad == 0xad xor 0x0 , 0x80 == 0x80 xor 0x0 , 0xa9 == 0xa9 xor 0x0 , 0x6f == 0x6f xor 0x0 , 0x37 == 0x37 xor 0x0 , 0x46 == 0x46 xor 0x0 , 0x91 == 0x91 xor 0x0 , 0x32 == 0x32 xor 0x0 , 0xb4 == 0xb4 xor 0x0 , 0xf7 == 0xf7 xor 0x0 , 0xa5 == 0xa5 xor 0x0 , 0xad == 0xad xor 0x0 , 0xd8 == 0xd8 xor 0x0 , 0x6b == 0x6b xor 0x0 , 0x35 == 0x35 xor 0x0 , 0x8c == 0x8c xor 0x0 , 0xe4 == 0xe4 xor 0x0 , 0x0 == 0x0 xor 0x0 , 0x20 == 0x20 xor 0x0 , 0x2e == 0x2e
进行仔细分析这些操作指令,会发现,前14行是我们输入的参数与它的下标索引值进行异或,后面的是我们输入的内容与索引异或后的结果再和一个类似于S盒的东西进行异或。那我们要反推出flag(就是我们输入的字符串)需要知道密文,直接密文与这个S盒异或再异或索引值就行了。
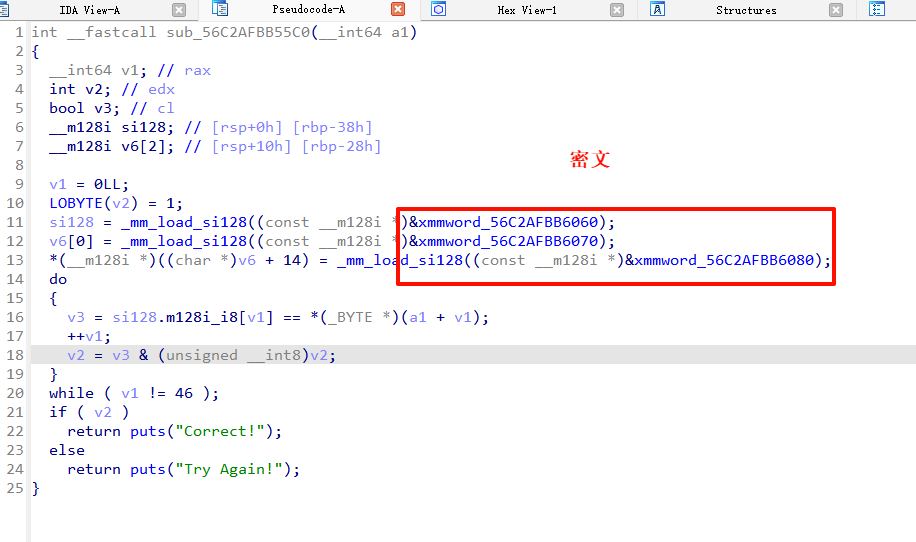
现在来提取密文
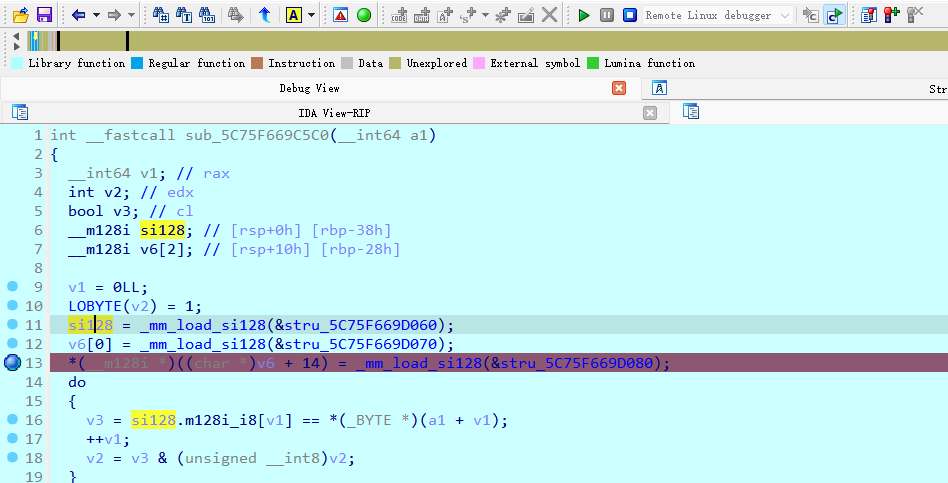
静态提取有问题,提数据最好是动态提取,这样大小端序也不会出问题
断点打在第13行,就可以直接读取 si128这个变量里面的值
提取后就可以写出解密脚本了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 enc=[0x14 , 0x27 , 0x70 , 0x6B , 0x9E , 0x94 , 0xF9 , 0x51 , 0x8E , 0x9F , 0xB2 , 0x51 , 0x69 , 0x73 , 0x2F , 0x46 , 0x53 , 0x05 , 0xDC , 0x36 , 0x69 , 0xA4 , 0x03 , 0x86 , 0x4B , 0xC4 , 0xC6 , 0xD5 , 0xE6 , 0x5F , 0x50 , 0x37 , 0xF7 , 0x5C , 0xC6 , 0x86 , 0xF9 , 0xA5 , 0xCA , 0x74 , 0x24 , 0xCC , 0xBA , 0x7E , 0x64 , 0x7E ] s=[0x50 ,0x67 ,0x21 ,0x2b ,0xce ,0xd7 ,0x84 ,0x3a ,0xf5 ,0xc2 ,0xc2 ,0x22 , 0x48 ,0x1d ,0x14 ,0x2a ,0x71 ,0x25 ,0xa7 ,0x73 ,0x3c ,0x9c ,0x72 ,0xfe , 0x3c ,0xb7 ,0xad ,0x80 ,0xa9 ,0x6f ,0x37 ,0x46 ,0x91 ,0x32 ,0xb4 ,0xf7 , 0xa5 ,0xad ,0xd8 ,0x6b ,0x35 ,0x8c ,0xe4 ,0x00 ,0x20 ,0x2e ] flag='' for i in range (len (enc)): flag+=chr (enc[i]^s[i]^i) print (flag)
re4 U.hap 这题给了一个hap后缀名文件,这是一道鸿蒙逆向题目。
上网搜查hap文件给的解释:.hap 文件是华为鸿蒙系统HarmonyOS的应用程序包格式,全称为 Harmony Ability Package 。它是鸿蒙原生应用安装和运行的基本单元,类似于 Android 的 APK 文件或 iOS 的 IPA 文件,包含了代码、资源、第三方库和配置文件。
鸿蒙应用文件概览:参考文献
https://shell.virbox.com/2025/11/14/%E9%B8%BF%E8%92%99%E5%BA%94%E7%94%A8%E6%96%87%E4%BB%B6%E6%A6%82%E8%A7%88%EF%BC%9Aabc%E3%80%81hap%E3%80%81har%E3%80%81hsp-%E5%92%8C-app/
hap文件就和安卓的apk文件一样,安卓的apk文件可以当成一个zip文件,去解压缩,这个同样也可以。因为它就是一个模块包,里面包含了代码,资源,第三方库等其他配置文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 entry_default ├─ets │ ├─modules.abc │ └─sourceMaps.map ├─libs │ └─arm64-v8a │ └─libentry.so ├─resources │ └─base │ ├─media │ │ ├─app_background.png │ │ ├─app_foreground.png │ │ ├─app_layered_image.json │ │ ├─background.png │ │ ├─foreground.png │ │ ├─layered_image.json │ │ └─startIcon.png │ └─profile │ ├─backup_config.json │ └─main_pages.json ├─.pages.info ├─module.json ├─pack.info ├─pkgContextInfo.json └─resources.index
ets目录包含应用的核心代码,modules.abc就是ArkTS 源代码编译后的字节码,sourceMaps.map 则是各个源文件的一些信息。
libs 目录放置应用引入的 so 库,支持多架构,每个架构放到对应的目录下。
resources 目录放置应用的资源文件,图片、配置、页面信息、音频等等文件都在这个目录下面。
对于逆向选手来说,改后缀为zip文件,解压缩,重点应该放在ets目录里的modules.abc文件。
ABC(Ark Bytecode,方舟字节码)是由鸿蒙的方舟编译器编译 ArkTS/TS/JS 生成的字节码文件,也就是可被解析执行的二进制文件,以 .abc 作为后缀名。ABC 文件包含应用所有的逻辑,类、方法、字段、调试信息、字符串、字面量等数据都在其中,通过分析这个文件,就可以逆向鸿蒙应用。
那么,我们知道以后遇到hap文件应该怎么去逆向了,但是如果没有好的工具也只能望眼欲穿秋水。没关系,大佬会出手,一位大佬把鸿蒙逆向所用的工具整理的很到位。这里引用一下他的博客。
https://github.com/Sciencekex/-wp-OHapp_re?tab=readme-ov-file
俺就不多赘述了,我是用的jadx-dev-all.jar工具去反编译了modules.abc文件。
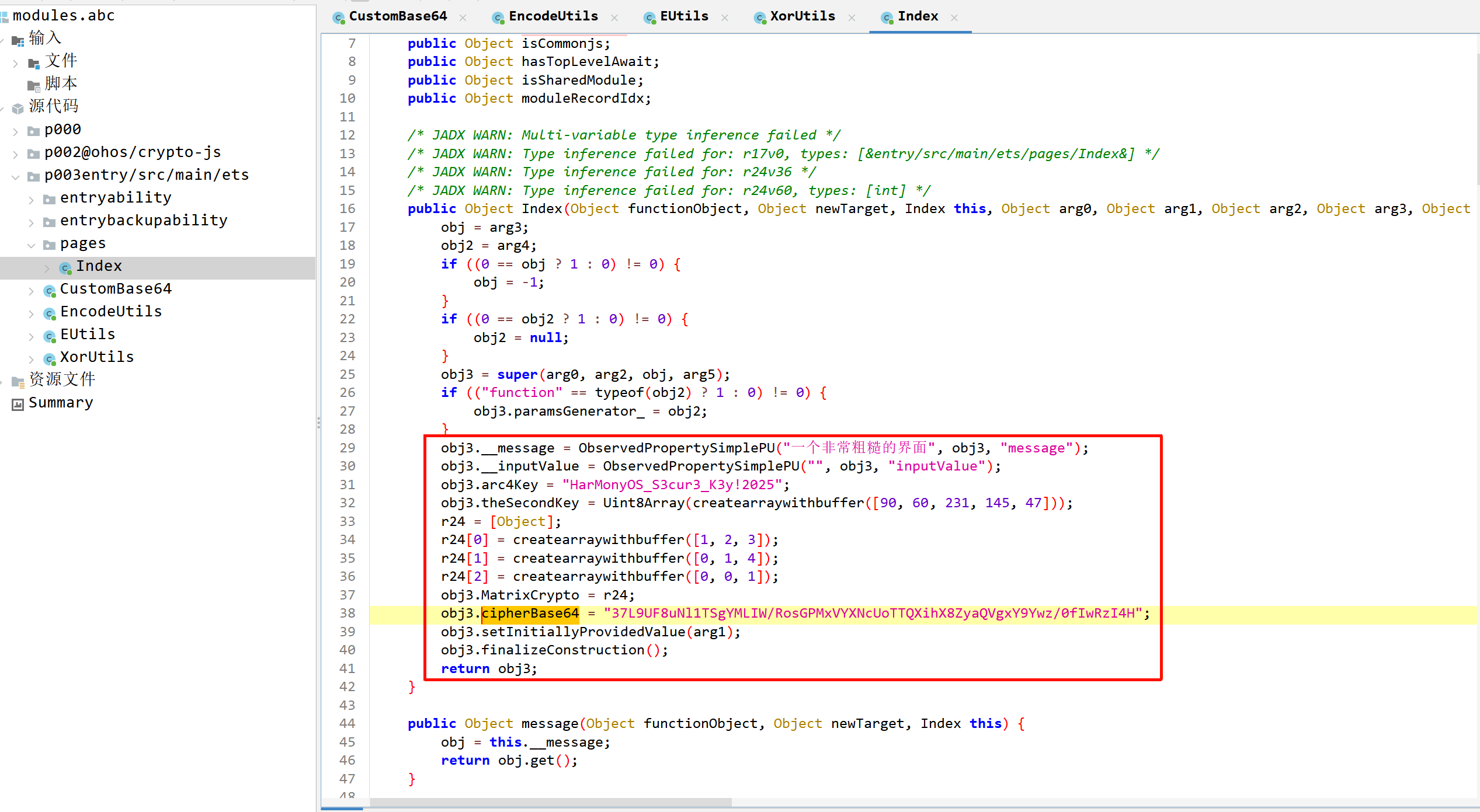
注意到Index这个类,能够知道这个是画出了程序的页面。
我们能从构造函数 Index() 知道一些有用的信息。
arc4Key:加密密钥, "HarMonyOS_S3cur3_K3y!2025"
theSecondKey:二级密钥, [90, 60, 231, 145, 47]
MatrixCrypto:3x3矩阵数组,用于加密,
cipherBase64:目标密文,"37L9UF8uNl1TSgYMLIW/RosGPMxVYXNcUoTTQXihX8ZyaQVgxY9Ywz/0fIwRzI4H"
继续往下分析,我们能看到校验逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public Object #1873697688084456659 #(Object functionObject, Object newTarget, Index this , Object arg0, Object arg1) { Button.createWithLabel("加密并比较" ); Button.id("encryptButton" ); Button.width("80%" ); Button.height(50 ); Button.margin(createobjectwithbuffer(["bottom" , 20 ])); Button.onClick(#4441499115937063224 #); return null ; } public Object #4441499115937063224 #(Object functionObject, Object newTarget, Index this ) { MatrixCrypto = import { default as MatrixCrypto } from "@normalized:N&&&entry/src/main/ets/EUtils&" ; if ((_lexenv_0_0_.cipherBase64 == MatrixCrypto.encrypt(_lexenv_0_0_.inputValue, _lexenv_0_0_.MatrixCrypto, _lexenv_0_0_.theSecondKey, _lexenv_0_0_.arc4Key) ? 1 : 0 ) != 0 ) { ldlexvar = _lexenv_0_0_; ldlexvar.showResultDialog("you are right!" ); return null ; } ldlexvar2 = _lexenv_0_0_; ldlexvar2.showResultDialog("try again!" ); return null ; }
大概逻辑就是,我们点击按钮后,就会去调用MatrixCrypto.encrypt()加密函数对输入的内容进行加密。然后与cipherBase64进行对比,如果一样的话就会弹出” you are right! “
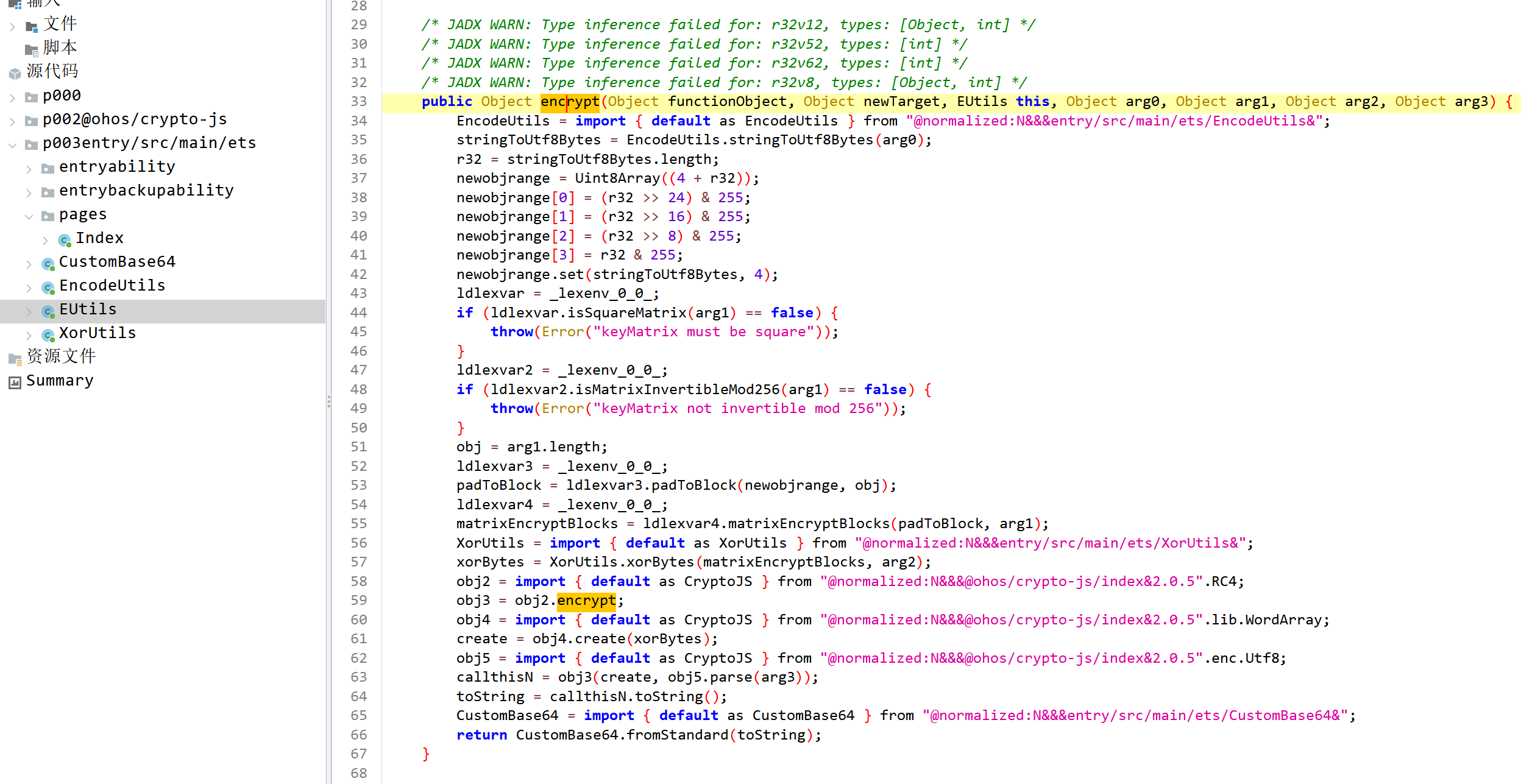
接着就要去分析这个encrypt函数了,看到底执行的什么加密。这个加密逻辑是在EUtils类里。
结合ai的分析,能知道这个加密流程:
第一步:字符串转UTF-8
1 stringToUtf8Bytes = EncodeUtils.stringToUtf8Bytes(arg0);
第二步:前置 4 字节长度
1 2 3 4 5 6 7 r32 = stringToUtf8Bytes.length; newobjrange = Uint8Array((4 + r32)); newobjrange[0 ] = (r32 >> 24 ) & 255 ; newobjrange[1 ] = (r32 >> 16 ) & 255 ; newobjrange[2 ] = (r32 >> 8 ) & 255 ; newobjrange[3 ] = r32 & 255 ; newobjrange.set(stringToUtf8Bytes, 4 );
就是把长度按照大端序塞进前4个字节里面。
第三步:按矩阵阶数补齐
1 2 obj = arg1.length; padToBlock = padToBlock(newobjrange, obj);
arg1 就是矩阵 MatrixCrypto,是 3x3,所以 arg1.length == 3。根据上面的那个校验函数里去调用了加密函数,看它的参数就知道此处arg1是MatrixCrypto。
arg0就是输入的明文inputValue。
arg2就是theSecondKey。
arg3是arc4Key,rc4加密的key。
接着看 padToBlock():
1 2 3 4 5 6 7 8 9 public Object padToBlock (..., Object arg0, Object arg1) { i = arg0.length % arg1; if ((0 == i ? 1 : 0 ) != 0 ) { return arg0; } newobjrange = Uint8Array(((arg0.length + arg1) - i)); newobjrange.set(arg0); return newobjrange; }
arg1对arg1取余,arg1是3,余数是0,1,2。如果余数是0的话,就会return arg0。如果不是就会放到一个更长的字节数组里面。
newobjrange.set(arg0);只把旧数据复制进去,没有给后面的新位置赋别的值。而 Uint8Array 新建时,剩余位置默认全是 0。
所以它会把数据补到 3 的倍数长度 ,补的是 0。
第四步:矩阵分组加密
1 matrixEncryptBlocks = matrixEncryptBlocks(padToBlock, arg1);
接着往下看看这个加密内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public Object matrixEncryptBlocks (Object functionObject, Object newTarget, EUtils this , Object arg0, Object arg1) { r24 = arg1.length; newobjrange = Uint8Array(arg0.length); i = 0 ; while (true ) { i2 = i; if ((i2 < arg0.length ? 1 : 0 ) == 0 ) { return newobjrange; } slice = arg0.slice(i2, i2 + r24); ldlexvar = _lexenv_0_0_; mulMatrixVectorMod256 = ldlexvar.mulMatrixVectorMod256(arg1, Array.from(slice)); for (i3 = 0 ; (i3 < r24 ? 1 : 0 ) != 0 ; i3 = tonumer(i3) + 1 ) { newobjrange[i2 + i3] = mulMatrixVectorMod256[i3] & 255 ; } i = i2 + r24; } }
它每次切出 r24 = arg1.length 个字节,也就是 3 字节一组 ,然后调用 mulMatrixVectorMod256。
1 2 3 4 5 6 7 8 9 10 11 12 13 public Object mulMatrixVectorMod256 (Object functionObject, Object newTarget, EUtils this , Object arg0, Object arg1) { obj = arg0.length; newobjrange = Array(obj); for (i = 0 ; (i < obj ? 1 : 0 ) != 0 ; i = tonumer(i) + 1 ) { i2 = 0 ; for (i3 = 0 ; (i3 < obj ? 1 : 0 ) != 0 ; i3 = tonumer(i3) + 1 ) { i2 += arg0[i][i3] * arg1[i3]; } newobjrange[i] = i2 & 255 ; } return newobjrange; }
这就是标准的:输出向量 = 矩阵 × 输入向量 mod 256。
因为 & 255 就等价于模 256,所以这一层可以准确写成:
按3字节分组 -> 3x3矩阵乘法 mod 256
第五步:XOR
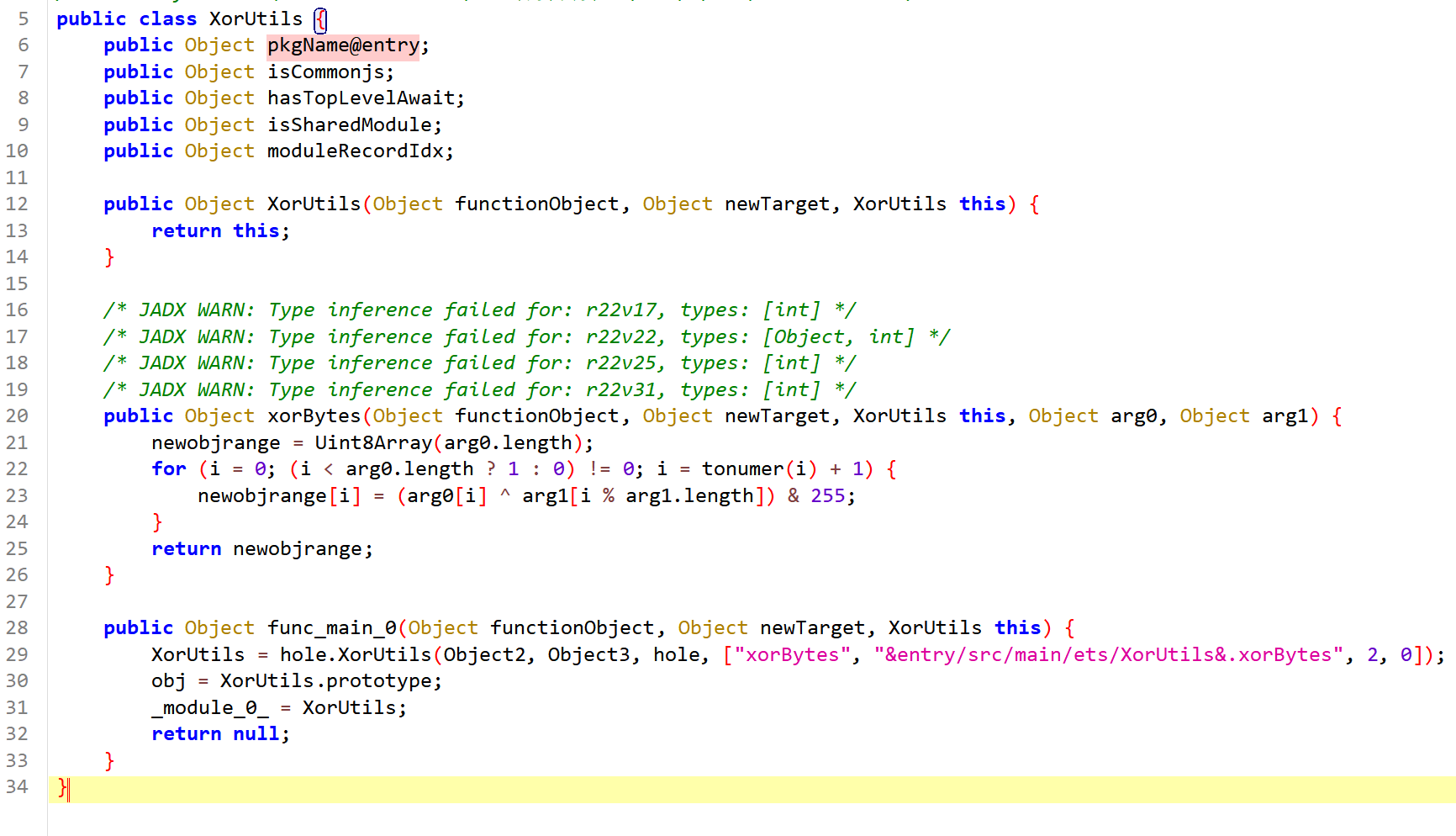
1 2 XorUtils = import { default as XorUtils } from "@normalized:N&&&entry/src/main/ets/XorUtils&" ; xorBytes = XorUtils.xorBytes(matrixEncryptBlocks, arg2);
去看XorUtils类
arg0是矩阵加密后的字节流,arg1是[90, 60, 231, 145, 47],i % arg1.length 表示循环使用 key。
这一层就是将矩阵加密结果与第二把 key 循环异或。
第六步:RC4
继续看encrypt()
1 2 3 4 5 6 7 obj2 = import { default as CryptoJS } from "@normalized:N&&&@ohos/crypto-js/index&2.0.5" .RC4; obj3 = obj2.encrypt; obj4 = import { default as CryptoJS } from "@normalized:N&&&@ohos/crypto-js/index&2.0.5" .lib.WordArray; create = obj4.create(xorBytes); obj5 = import { default as CryptoJS } from "@normalized:N&&&@ohos/crypto-js/index&2.0.5" .enc.Utf8; callthisN = obj3(create, obj5.parse(arg3)); toString = callthisN.toString();
xor后的结果放到WordArray里面,然后与密钥arg3进行RC4加密。
第七步:自定义Base64
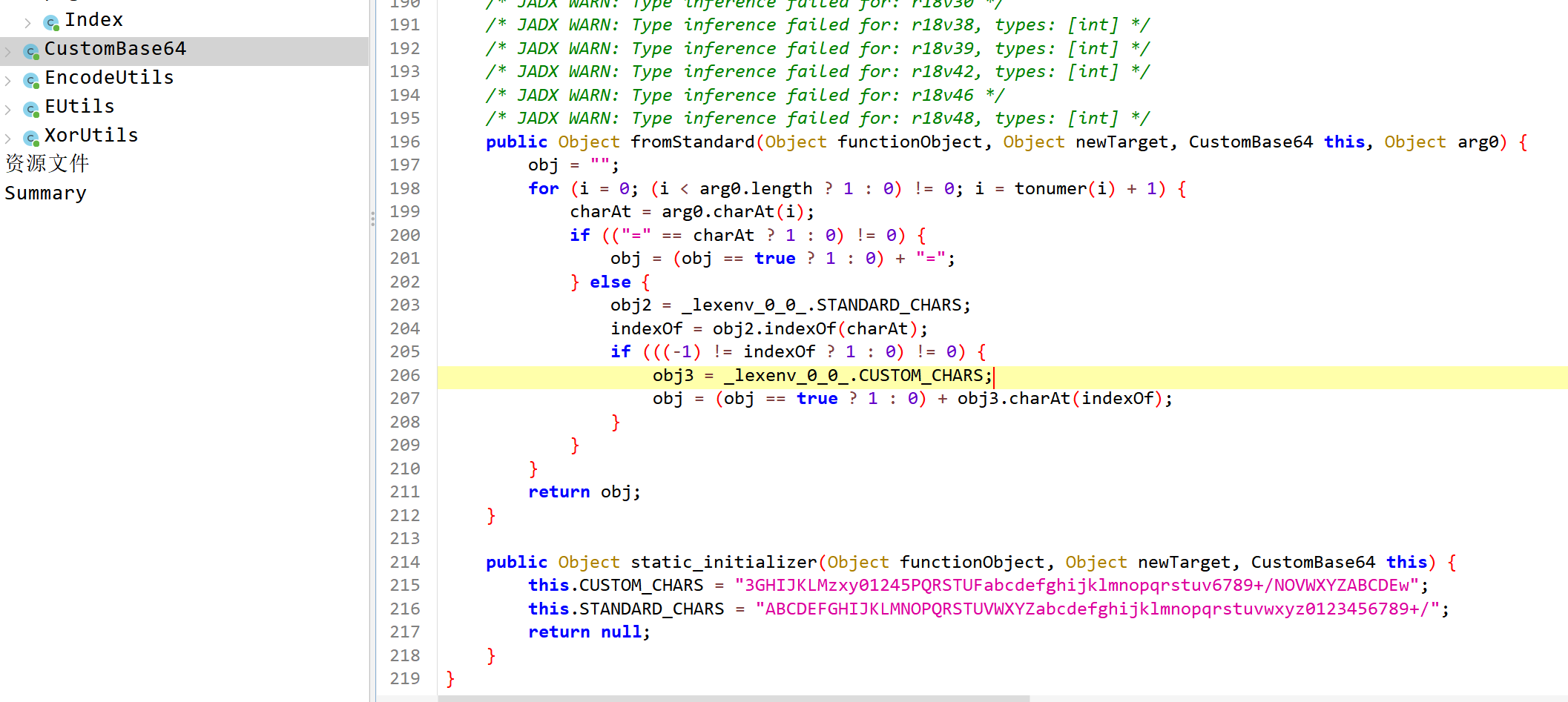
1 2 CustomBase64 = import { default as CustomBase64 } from "@normalized:N&&&entry/src/main/ets/CustomBase64&" ; return CustomBase64.fromStandard(toString);
这个需要看CustomBase64类了
能知道变表,也就能解了。这个就是rc4加密后的结果用base64变表加密了。
解密的顺序就是
自定义Base64 -> RC4解密 -> XOR -> 逆矩阵解密 -> 去掉4字节长度 -> UTF-8
那进行解密,下面的脚本ai给的,ai还是太强了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 import base64cipher_custom = "37L9UF8uNl1TSgYMLIW/RosGPMxVYXNcUoTTQXihX8ZyaQVgxY9Ywz/0fIwRzI4H" arc4_key = b"HarMonyOS_S3cur3_K3y!2025" xor_key = [90 , 60 , 231 , 145 , 47 ] M = [ [1 , 2 , 3 ], [0 , 1 , 4 ], [0 , 0 , 1 ], ] CUSTOM_CHARS = "3GHIJKLMzxy01245PQRSTUFabcdefghijklmnopqrstuv6789+/NOVWXYZABCDEw" STANDARD_CHARS = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" M_INV = [ [1 , 254 , 5 ], [0 , 1 , 252 ], [0 , 0 , 1 ], ] def custom_to_standard (s: str ) -> str : out = [] for ch in s: if ch == "=" : out.append("=" ) else : idx = CUSTOM_CHARS.index(ch) out.append(STANDARD_CHARS[idx]) return "" .join(out) def rc4_crypt (data: bytes , key: bytes ) -> bytes : S = list (range (256 )) j = 0 for i in range (256 ): j = (j + S[i] + key[i % len (key)]) % 256 S[i], S[j] = S[j], S[i] i = 0 j = 0 out = bytearray () for byte in data: i = (i + 1 ) % 256 j = (j + S[i]) % 256 S[i], S[j] = S[j], S[i] k = S[(S[i] + S[j]) % 256 ] out.append(byte ^ k) return bytes (out) def xor_bytes (data: bytes , key ) -> bytes : return bytes ((data[i] ^ key[i % len (key)]) & 0xFF for i in range (len (data))) def mul_matrix_vector_mod256 (mat, vec ): n = len (mat) out = [] for i in range (n): s = 0 for j in range (n): s += mat[i][j] * vec[j] out.append(s & 0xFF ) return out def matrix_decrypt_blocks (data: bytes , inv_mat ) -> bytes : n = len (inv_mat) assert len (data) % n == 0 out = bytearray (len (data)) for i in range (0 , len (data), n): block = list (data[i:i+n]) dec = mul_matrix_vector_mod256(inv_mat, block) for j in range (n): out[i + j] = dec[j] return bytes (out) def decrypt (): std_b64 = custom_to_standard(cipher_custom) print ("[+] Standard Base64:" , std_b64) rc4_cipher = base64.b64decode(std_b64) print ("[+] RC4 ciphertext hex:" , rc4_cipher.hex ()) xored = rc4_crypt(rc4_cipher, arc4_key) print ("[+] After RC4 decrypt:" , xored.hex ()) mat_enc = xor_bytes(xored, xor_key) print ("[+] After XOR restore:" , mat_enc.hex ()) padded_plain = matrix_decrypt_blocks(mat_enc, M_INV) print ("[+] After matrix decrypt:" , padded_plain.hex ()) msg_len = int .from_bytes(padded_plain[:4 ], "big" ) print ("[+] Message length:" , msg_len) plaintext = padded_plain[4 :4 +msg_len].decode("utf-8" ) print ("[+] Plaintext:" , plaintext) return plaintext if __name__ == "__main__" : decrypt()
DASCTF{H4rmOny0S_Mult1_L4y3r_Crypt0_M4st3r!}
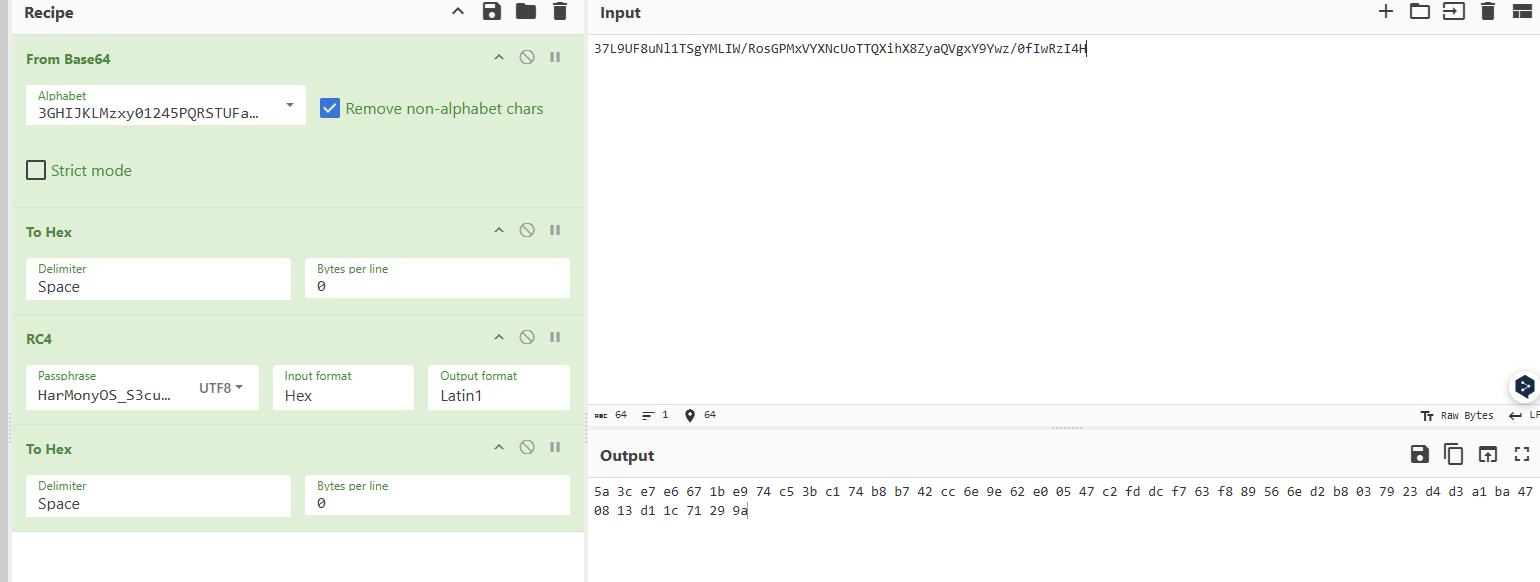
或者将前面两步直接用在线求解
后面的异或和逆矩阵解密写个脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 data = bytes .fromhex("5a 3c e7 e6 67 1b e9 74 c5 3b c1 74 b8 b7 42 cc 6e 9e 62 e0 05 47 c2 fd dc f7 63 f8 89 56 6e d2 b8 03 79 23 d4 d3 a1 ba 47 08 13 d1 1c 71 29 9a" ) xor_key = [0x5a , 0x3c , 0xe7 , 0x91 , 0x2f ] M_INV = [ [1 , 254 , 5 ], [0 , 1 , 252 ], [0 , 0 , 1 ], ] def xor_restore (data, key ): return bytes (data[i] ^ key[i % len (key)] for i in range (len (data))) def mul (mat, vec ): out = [] for i in range (3 ): s = 0 for j in range (3 ): s += mat[i][j] * vec[j] out.append(s & 0xff ) return out def matrix_decrypt_blocks (data, inv ): out = bytearray () for i in range (0 , len (data), 3 ): block = list (data[i:i+3 ]) out.extend(mul(inv, block)) return bytes (out) x = xor_restore(data, xor_key) print ("xor后:" , x.hex ())p = matrix_decrypt_blocks(x, M_INV) print ("矩阵解密后:" , p.hex ())n = int .from_bytes(p[:4 ], "big" ) print ("长度:" , n)print ("明文:" , p[4 :4 +n].decode())