
ISCC2025 re部分讲解
ISCC2025 re部分
rc4
RC4加密算法是比较简单的对称加密算法,重点是在秘钥流生成器那里
1、先初始化S盒(256个字节,用来作为密钥流生成的种子1)
按照升序,给每个字节赋值0,1,2,3,4,5,6…..,254,255
S = list(range(256))
2、初始密钥(由用户输入),长度任意
如果输入长度小于256个字节,则进行轮转,直到填满
例如输入密钥的是1,2,3,4,5 , 那么填入的是1,2,3,4,5,1,2,3,4,5,1,2,3,4,5……..
由上述轮转过程得到256个字节的向量(用来作为密钥流生成的种子2)
3、KSA-密钥调度算法
S盒是0-255
然后根据密钥打乱S盒:根据密钥里的每一个字符,算出新的索引值 j ,然后S[i] , S[j] 互换位置。
经过 256 次交换后,就拿到了新的S盒。
按照下列规则进行
从第零个字节开始,执行256次,保证每个字节都得到处理
1 | j = 0 |
这样处理后的状态向量S几乎是带有一定的随机性了
4、PRGA - 伪随机子生成算法
KSA完成后,我们拿到的是一个被打乱的S盒,接下来的PRGA就用它不断产生密钥流字节。
1 | i=j=0 #初始化 |
最后得到K,K就是我们最后要与明文进行异或的密钥流
然后进行异或
out.append(c ^ K) #按位异或
RC4在逆向里的特征:
1.有一个256字节的数组
2.初始化成0-255(可能魔改)
3.多次swap S[i] 和 S[j] 进行交换
4.最后密钥流和明文异或
5.多次%256
RC4本质上其实就是异或,它是明文和密钥流的异或,如果可以动态调试,那是可以调出密钥流的,当然S盒也可以调出来。
加密的时候是 明文和密钥流异或得到密文,解密的时候将密文与相同的密钥流再次异或就能恢复明文。因为密钥流是依靠密钥生成的(S盒固定),所以知道密钥和密文,明文就进行一次RC4加密就行了。只要不破坏RC4的对称性,也是可以动调拿到flag的。
下面的脚本是标准rc4加密算法,python版本
1 | def rc4(data,key): |
花指令
什么是花指令?
花指令实质就是一串垃圾指令,它与程序本身的功能无关,并不影响程序本身的逻辑。在软件保护中,花指令被作为一种手段来增加静态分析的难度,使程序无法很好的反编译。
花指令大致可以分为可执行花指令和不可执行花指令。
学习花指令的准备
在一个程序中想要发现理解花指令就必须要理解明白汇编指令。
1 | push ebp —-把基址指针寄存器压入堆栈 |
我们还需要认识一些常见的机器码
| 机器码 | 指令 | 格式 | 说明 |
|---|---|---|---|
| 0xE8 | CALL | E8 xx xx xx xx | CALL 指令后面跟的是一个4字节的相对偏移地址(相对于下一条指令的地址) |
| 0xE9 | JMP | E9 xx xx xx xx | JMP 指令后面跟的是一个4字节的相对偏移地址 |
| 0xEB | JMP(短跳方式) | EB xx | JMP 指令后面跟的是一个1字节的相对偏移地址 |
| FF 15 | CALL dword ptr [addr] | FF 15 xx xx xx xx | 到内存地址addr处,取出一个4字节值,把这个4字节值当作函数地址然后call 这个函数地址 |
| FF 25 | JMP dword ptr [addr] | FF 25 xx xx xx xx | 从指定地址中读取一个地址,然后 JMP 到那个地址 |
不可执行花指令
花指令虽然被插入到了正常代码的中间,但是并不意味着它一定会得到执行。不可执行花指令就是这样的,这些指令看起来是在代码里面,但是程序运行起来的时候根本不会走到这里。这是利用反汇编器的静态分析算法的缺陷使得代码在插入的花指令处反编译出错。
如果插入的花指令是一个操作码,比如0x33(xor指令的操作码),0xE8(CALL指令操作码)等,那么后面程序原本的机器码就会被认为是这个操作码的操作数,从而导致反汇编引擎的解析错误。
在设计这类花指令时要通过构造 必然条件 或者 互补条件,使得程序在实际执行时绕过垃圾数据,这样不会影响程序正常执行。
举个例子
1 | xor eax, eax |
常见的构造方式
一,无条件跳过,上面的例子就是无条件跳过
二,永真永假条件
1 | xor eax, eax |
因为eax = eax永远成立,所以jne fake_block永远不会跳转,那么fake block这一块就是花指令。
三,ret后面藏花指令
1 | mov eax, 1 |
ret 后面正常流程已经结束了,后面的指令如果没有别的地方跳进来,通常也是花指令。
可执行花指令
花指令在程序执行过程中会被执行,但执行这些代码没有任何意义,执行前后不改变任何寄存器的值,也不改变程序执行逻辑和结果,目的是加大静态分析的难度,或是混淆特征码,绕过特征检测。
最简单的例子
1 | push eax |
push eax 把eax压栈
pop eax 再把原值弹出来
最终eax 没有变,这就是最典型的可执行花指令。
常见的构造方式:call+ret
call 指令:将下一条指令的地址压入栈作为返回地址,然后跳转到函数地址,相当于push 下一条指令地址,mov eip,函数地址
ret指令:从栈顶弹出返回地址,压入eip,类似于pop eip
push 入栈,pop 出栈,这些操作指令进行组合使用,就能使返回地址跳到任意地方,从而构造花指令
举个例子

call loc_40135E 它会把 0x0040135D(下一条指令地址)压入栈中作为返回地址,并且正常调用 loc_40135E。
在loc_40135E 开始执行时,0x36是一个无意义的字节,然后执行add [esp+68h+var_68], 8
esp指的是栈顶的内存地址,当前栈顶存放的内存地址是0x0040135D,这条指令的作用是,将栈顶存放的那个 dword 值(即 0x40135D)加上 8,然后把结果再写回栈顶。所以新的返回地址就变成了0x40135D + 8 = 0x401365。
那就说明,这个call相当于跳转到了0x401365执行,从call 指令到新的返回地址之间的指令都没有用了,这部分是花指令,可以直接nop掉。
因为这种花指令是可以执行的,所以还有一种方法就是动态调试,直接看返回地址是谁,然后把没用的nop掉,这样不用计算返回地址,更方便一点。
决赛-CrackMe
这道题的考点是花指令+RC4
jmp $+5 是什么意思呢?
$ 表示当前指令地址
$+5 = 当前地址再往后 5 个字节
先找到Windows 程序的入口函数 WinMain,进行分析
这个是一个Windows图形程序的入口函数,它的作用就是
注册窗口类 -> 创建窗口 -> 显示窗口 -> 进入消息循环 -> 程序结束返回
WndClass.lpfnWndProc = (WNDPROC)sub_1400013E0;
这个是指定窗口过程函数,也就是这个窗口收到消息时由谁来处理,这个函数一般是整个程序的逻辑重点,真正的校验逻辑,按钮响应,输入处理,大概率都在这里。
程序创建窗口后,并不会自己一直往下跑,而是不断等待系统消息,然后处理这些消息。GetMessageW是从消息队列里面去取消息,可能的消息有:鼠标点击,键盘输入,窗口重绘,关闭窗口等,只要程序没有退出,它就会一直循环取消息。
TranslateMessage是把键盘消息做一些转换,比如把按键消息翻译成字符消息。
DispatchMessageW是把消息分发给窗口过程函数处理,也就是前面设置的sub_1400013E0
所以这里的流程就是
系统产生消息 → GetMessage 取出 → DispatchMessage 转交给 sub_1400013E0 处理

lpfnWndProc: 这是“窗口过程”函数的指针。它告诉系统:“只要有人对我这个窗口做了任何事(点按钮、按键盘、关闭窗口、输入信息),请立刻调用 sub_1400013E0 来处理。”
所以关键逻辑还是要看这个函数的。
跟进这个函数看一下,发现爆红了,说明有花指令。
什么是花指令呢?花指令实质就是一串垃圾指令,它与程序本身的功能无关,并不影响程序本身的逻辑。
比如一些简单的跳转,是不可执行花指令。
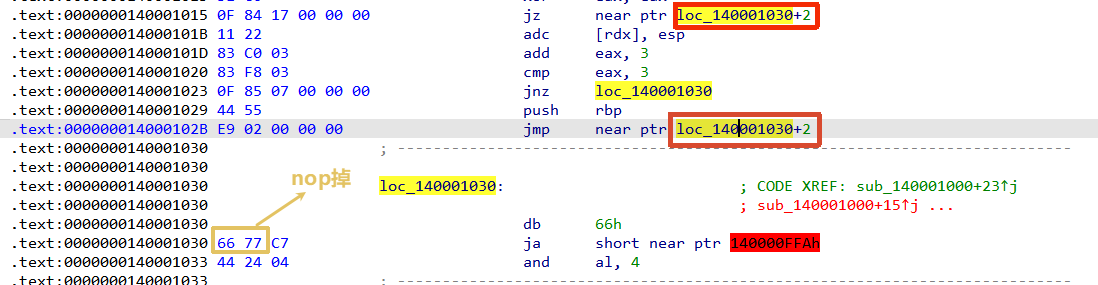
这里jz和jmp都是要跳转到 loc_140001030也就是地址0x140001030处吗?
其实不然,后面还跟了+2
说明跳过了 0x66 和 0x77 这两个字节,从0xC7字节开始的。那么这两个就是垃圾字节,ida并不会去执行他们,会跳过他们。但是这个影响了反汇编,导致不能正确反编译出来。我们需要把这两个字节给nop掉。
按U 取消当前位置的代码定义,恢复成未定义状态。按P,就是把当前位置定义成一个函数。
什么是宽字符?
一个字符(char)占用1个字节(8位),只能表示256 个不同的符号。
宽字符 (wchar_t) 是为了处理多语言文本而设计的,大小是2字节(16位),采用UTF-16编码
wcslen 是标准 C/C++ 库中的函数,全称是 Wide Character String Length。
- 功能:计算一个宽字符串(
wchar_t类型)的长度。
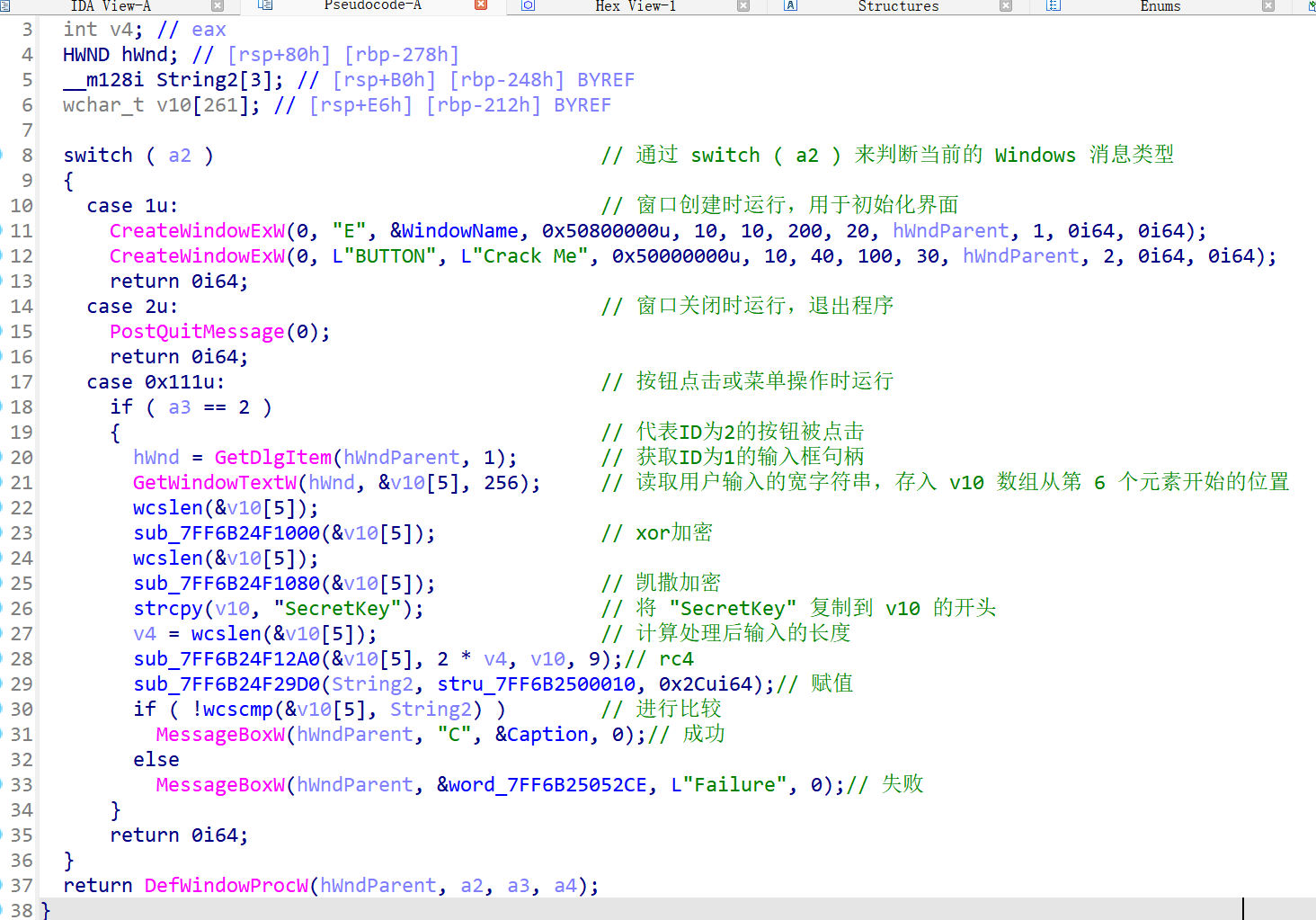
第一个加密函数
经过花指令nop后,反编译的效果不是很好,这里要对a1,也就是我们输入的字符串进行异或,但是不清楚异或的值,那就进行动态调试。
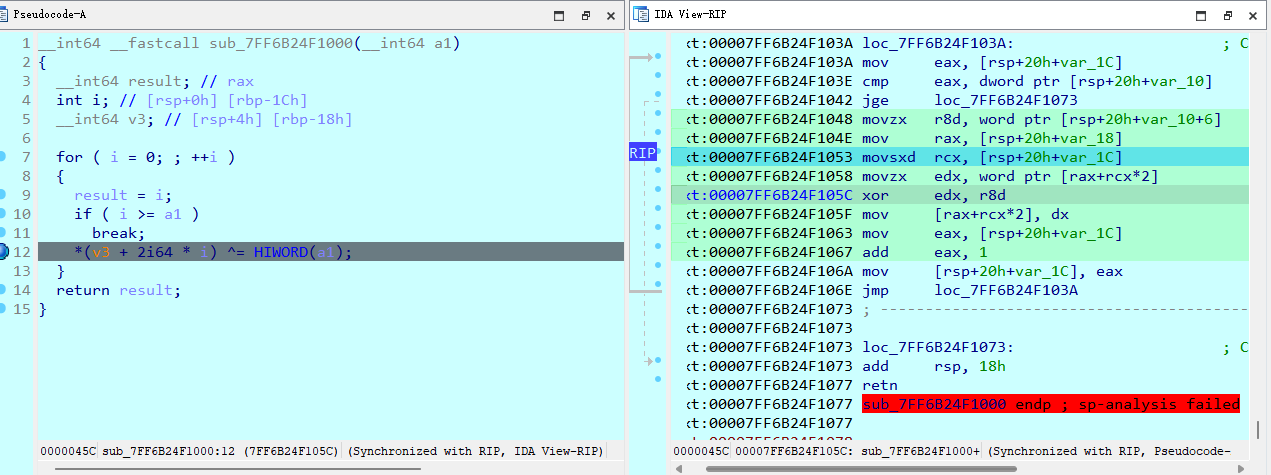
循环从 loc_7FF6B24F103A 开始:
mov eax, [rsp+20h+var_1C]: 把循环变量(也就是i)拿到寄存器eax里。cmp eax, dword ptr [rsp+20h+var_10]: 把i和一个数字比较。这个数字就是字符串的长度(a1的低 32 位)。jge loc_7FF6B24F1073: 如果i大于或等于长度,说明处理完了,直接跳出循环去执行retn(返回)。
如果没跳出,就开始执行加密:
- 取密钥:
movzx r8d, word ptr [rsp+20h+var_10+6]- 这里就是获取 65 (0x41) 的地方
- 注意这个偏移量 **
+6**。原本a1是一个 64 位(8 字节)的长整数。 +0到+1字节是第一个 WORD。+6到+7字节是最高位的那个 WORD。- 这证实了:异或密钥确实是从
a1这个参数的高位截取出来的。
- 定位字符:
movzx edx, word ptr [rax+rcx*2]rax存的是字符串的首地址。rcx存的是当前的索引i。- **
*2**:因为是宽字符(每个占 2 字节),所以索引要乘以 2 才能找到正确的内存位置。 - 这行代码把当前的字符读到了
edx寄存器里。
- 异或运算:
xor edx, r8d当前字符 ^ 0x41。
- 写回内存:
mov [rax+rcx*2], dx- 把异或后的结果(在
edx里)写回到原来的内存位置,完成了原地加密。
- 把异或后的结果(在
add eax, 1: 相当于 C 语言里的i++。jmp loc_7FF6B24F103A: 跳回循环开头,继续处理下一个字符。
第二个加密函数
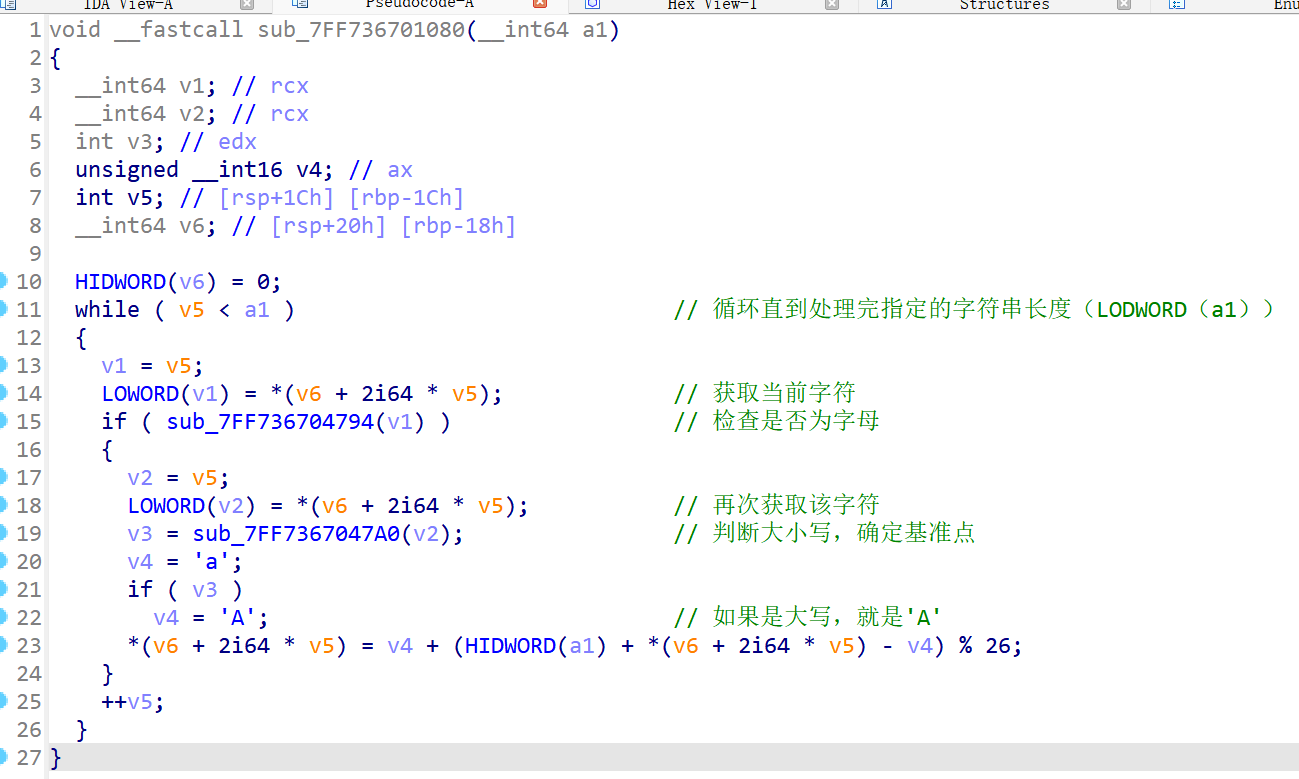
在这里,v5代表的就是一个索引值。
$$
\text{目标内存地址} = \text{基地址} (v6) + (\text{每个元素的大小} \times \text{索引} v5)
$$i64 只是告诉编译器,把这个乘法的结果当作一个 64 位的整数来处理,防止在计算超大内存地址时溢出。
iswctype是 C 标准库中的一个函数
1 | int iswctype(wint_t c, wctype_t desc); |
根据 指定的分类描述符(desc),测试宽字符 c 是否属于该类别。
它是 isalpha、isdigit、isspace 等所有字符检查函数的通用底层实现。
比如说:调用 iswalpha(c) 在底层实际上就是调用 iswctype(c, _ALPHA)。
它的返回值是一个整数,但是逻辑类似于布尔值。
- 如果指定的宽字符
c具有desc参数所指定的属性,函数返回一个非零值。 - 如果该字符不具备该属性,或者传入的字符是
WEOF(宽字符的文件结束符),则返回 0。
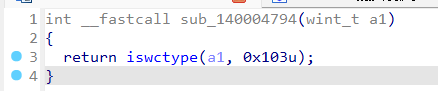
那0x103是什么意思?
iswctype 的第二个参数是一个位掩码(Bitmask)。在 Windows 的头文件(如 ctype.h 或 wctype.h)中,每种字符属性都对应一个二进制位:
| 常量名 (Windows CRT) | 十六进制值 | 含义 |
|---|---|---|
_UPPER |
0x0001 |
大写字母 |
_LOWER |
0x0002 |
小写字母 |
_DIGIT |
0x0004 |
数字 (0-9) |
_SPACE |
0x0008 |
空白字符 |
_PUNCT |
0x0010 |
标点符号 |
_ALPHA |
0x0100 |
字母字符 (Alphabetic) |
我们把这些标志位组合起来
$$
0x100 (\text{ALPHA}) + 0x002 (\text{LOWER}) + 0x001 (\text{UPPER}) = 0x103
$$
所以,0x103 代表的是任何字母(无论大小写)。
凯撒加密
凯撒加密的核心操作是位移(Shift),凯撒加密就是将明文中的每一个字母,在字母表上向左或向右推移固定数量的位置。
$$
c_{new} = \text{Base} + ((c_{old} - \text{Base} + \text{Shift}) \pmod{26})
$$
Base 根据 c 的大小写取 'A' 或 'a'。
先把字符减去基准(’A’ 或 ‘a’),转成 0-25 的数字。
再加上位移量
% 26:处理超出 Z 之后回到 A 的循环。
再加上Base:最后加回基准,还原成字符编码。
1 | def caesar_encrypt(text, shift): |
这里需要进行动态调试,去看它的位移。这个位移是3。
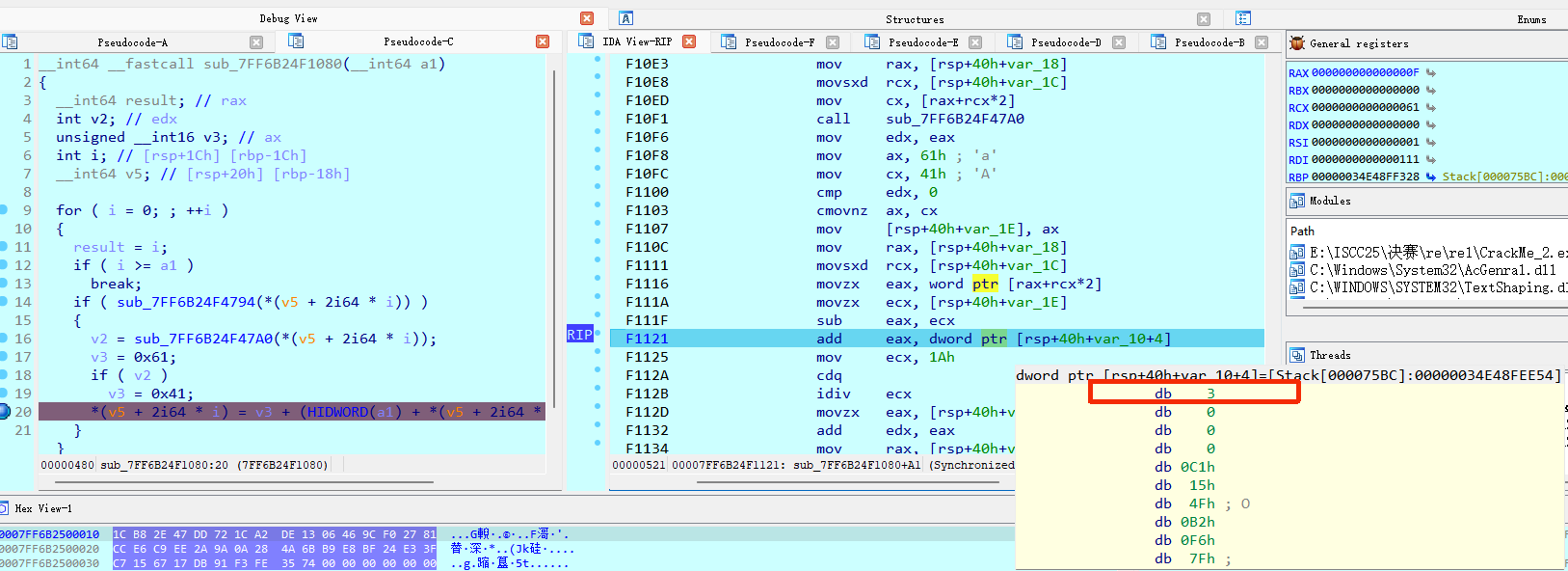
第三个加密函数
什么是RC4 ,RC4是一种对称加密算法。它的本质就是利用你的“密钥”,生成一串无限长的随机数字(密钥流),然后把这串数字和你真正的原文进行异或(XOR)。
逻辑也就是明文进行逐个字节与0x41进行异或,然后进行凯撒加密是加3,最后进行rc4加密,rc4的密钥是”SecretKey”。
需要注意的是异或加密和凯撒加密都是对宽字符进行的。
1 | def rc4(data, key): |
练习题-NewStar25-week3-采一朵花,送给艾达(2)
先查壳,这个是程序是无壳64位,直接放到ida里面进行分析。
发现有爆红的地方,ida没有正确反编译出来,直接去看汇编窗口。
我们能够看到花指令
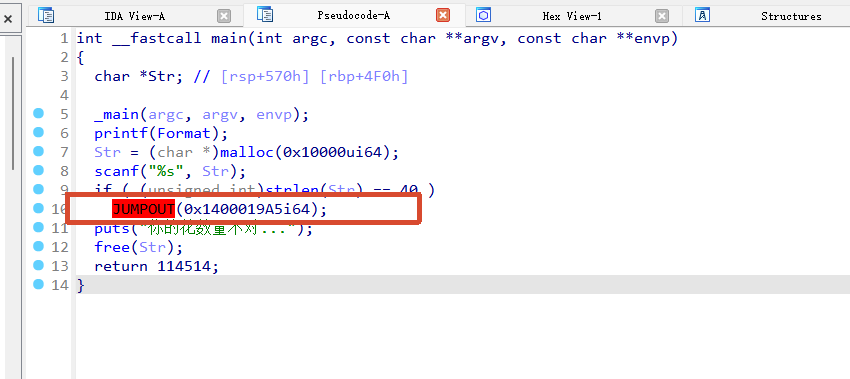
这个+1相当于跳过了0xE8这个字节,从0x48开始,说明0xE8就是一个垃圾字节,不执行。
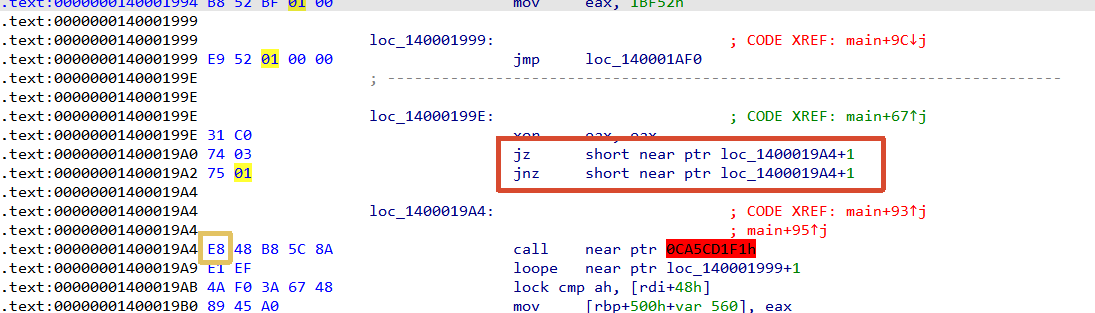
所以按U,将这个去除定义,然后把0xE8这个字节nop掉,然后在main函数的函数头,按U解除这个函数定义,再按P,去重新定义这个main函数。 那main函数就能被正确反编译了。
发现关键函数rc4_init,说明这个用到了RC4加密算法,keygen函数里面存放的就是key吧,双击一下,发现爆红。依旧是花指令。
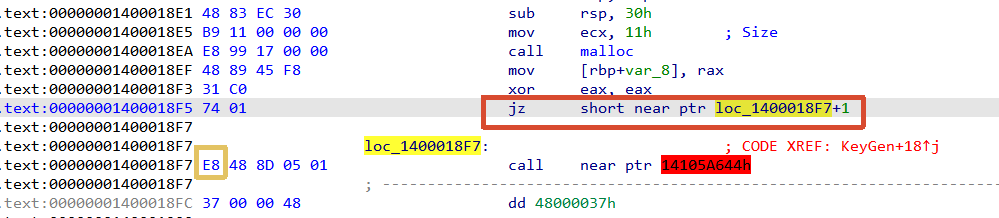
它会把0xE8跳过,去执行后面的指令,所以0xE8是垃圾字节,但是因为0xE8是call 指令,ida错误的识别了,需要把它nop掉。
使用同样的方法去nop,然后在这个keygen函数头去按U解除定义,再按P重新定义这个函数。
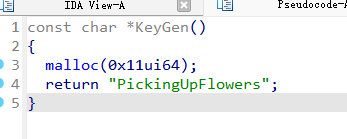
拿到rc4 的key “PickingUpFlowers”
接着看rc4_crypt函数,发现伪代码不完整,还是有花指令。
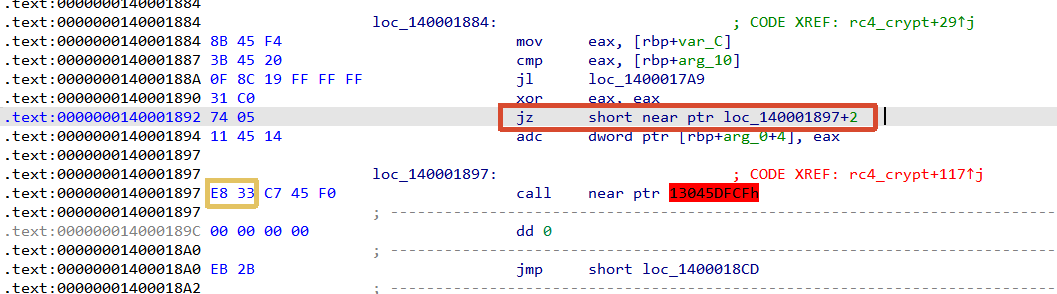
还是一样的,这个是+2,也就是跳过了0xE8和0x33两个字节,这两个字节是垃圾字节,但是被ida错误反汇编成了call指令,需要把这两个字节nop掉。
还是一样的方法,我们nop完后,找到函数头,进行重定义。
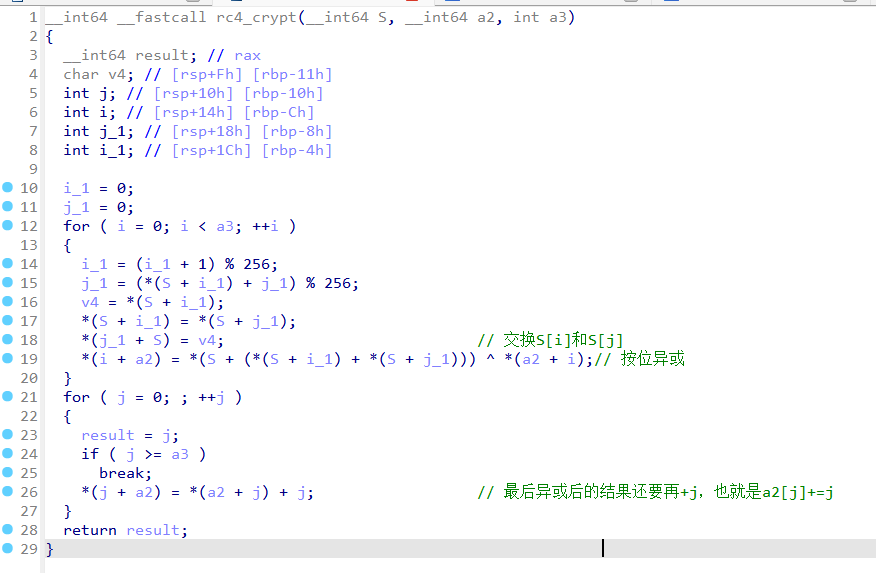
分析后就是rc4加密,最后的结果保存到a2里,然后做一个加法a2[j] += j
我们现在知道了rc4的加密部分,但还不知道rc4的初始化
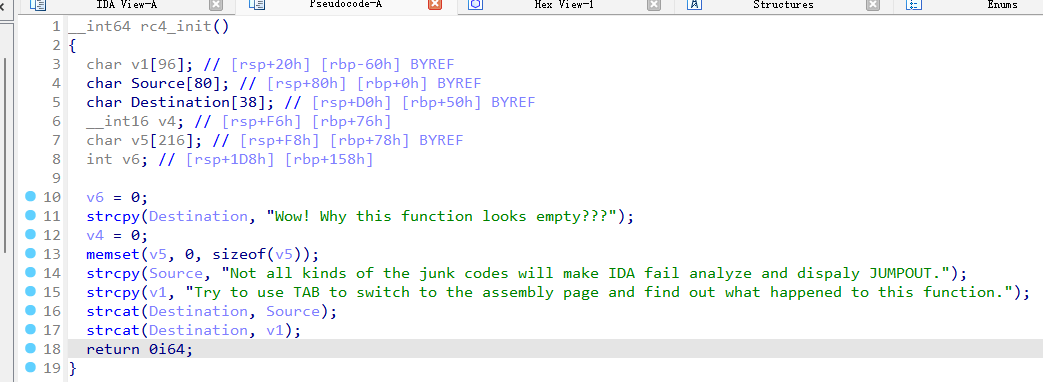
看这个初始化函数,并没有明确给出rc4的S盒初始化的过程。我们可以动调,直接看S盒。
在 rc4_crypt(v5, v6, v9); 打上断点。
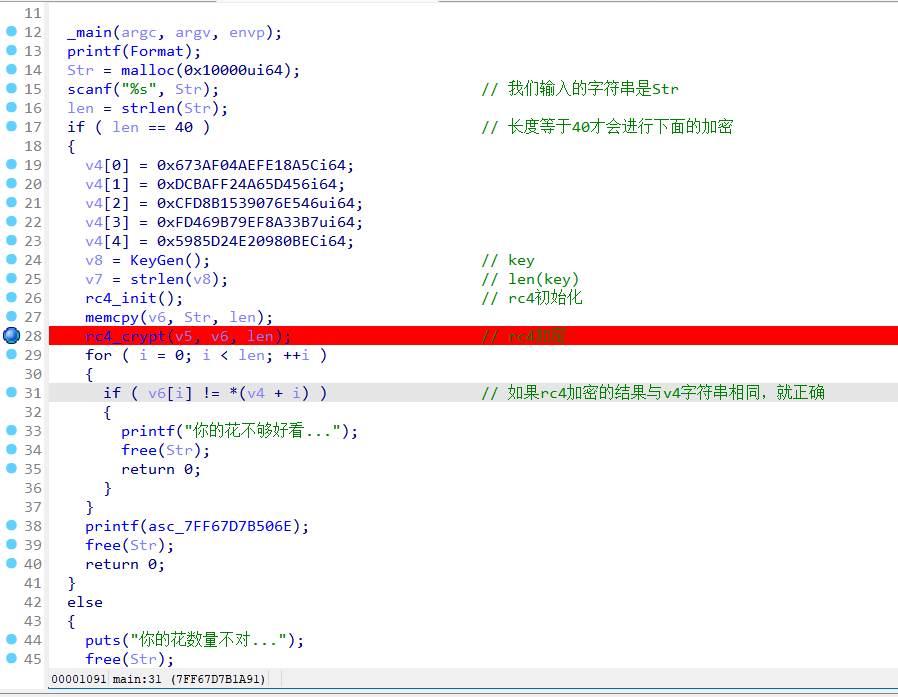
运行起来后,先取一下rc4的密文,也就是v4的值
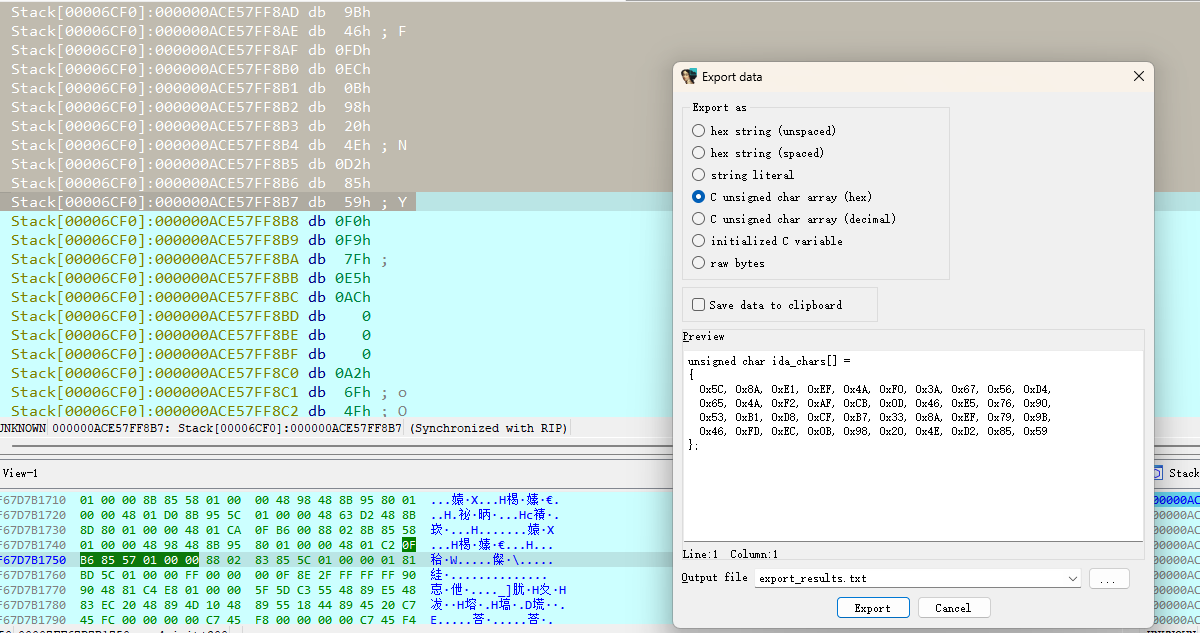
然后看 rc4_crypt(v5, v6, v9); 的第一个参数,v5,它就是传的S盒。
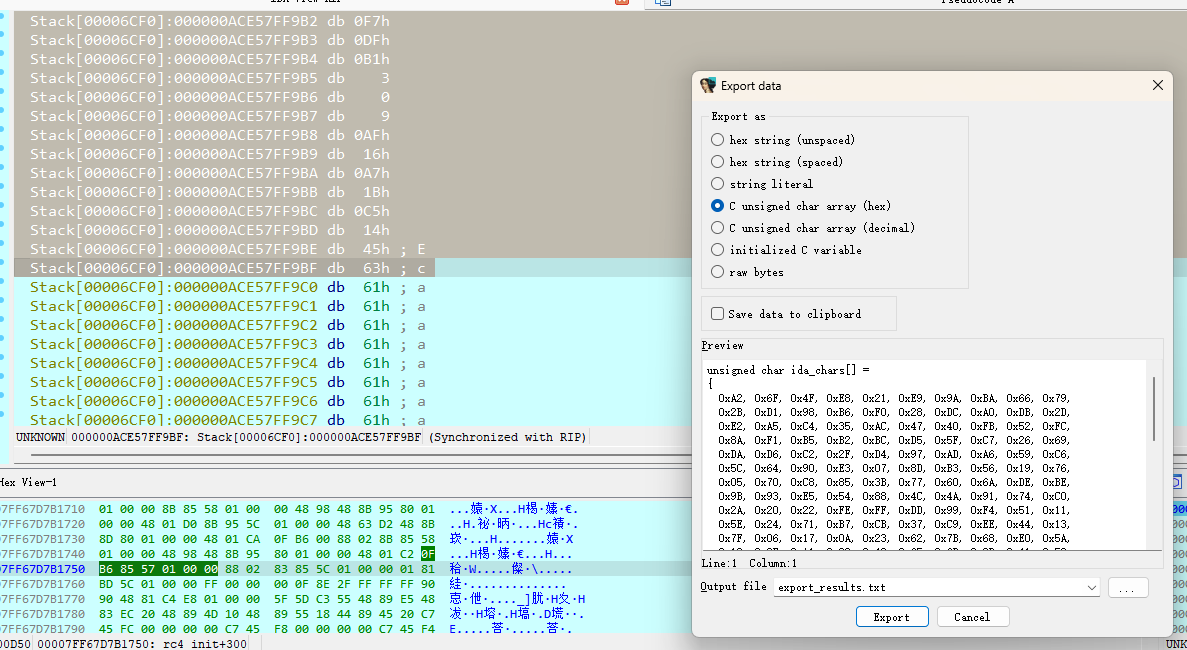
取一下就行,然后就能写出逆向脚本了,不同的是,它加密时最后需要+j,那解密的话需要先把密文-j,然后再进行rc4解密。
脚本如下
1 | def rc4(data,key): |
flag{WO0o0O0w_So0Oo0o_m4Ny_F1oO0o0oW3R5}
XXTEA
XXTEA是一种分组密码算法,可以简单理解为TEA和XTEA的升级版。
XXTEA是可变长度分组,按照32位(也就是4字节)数组进行处理。密钥长度是128位,就是4个32位整数。
与 TEA/XTEA 不同,XXTEA 不是固定只处理两个 32 位字,而是对整个字数组循环更新。
在每一轮中,每个字的更新都依赖于:
- 左右相邻字
- 当前轮常量 sum
- 由
(p & 3) ^ e选出的子密钥 - 若干移位、异或、加法混合
这样就能实现混淆和扩散。
加密时从 sum = 0 开始,每轮 sum += DELTA;
解密时从 sum = rounds * DELTA 开始,每轮 sum -= DELTA。
标准XXTEA的核心公式就是
1 |
z和y代表的是相邻的两个字,进行一些移位,还有轮常量 sum,密钥的选择。
n是待加密数据个数
XXTEA算法的解密同样只是对加密算法的数据处理顺序进行倒置,同时加法改减法(减法改加法)。
识别特征:
1.轮数是rounds = 6 + 52 / n
2.MX 公式的实现:左移右移,异或操作,标准的特征是z>>5^y<<2这些,但有的题也可能魔改。
3.delta值,这个值不断参与算法,但不会受到输入的影响,一般是0x9e3779b9,但也会改变。注意**-0x61c88647=0×9E3779B9**
xxtea的标准实现过程,加解密(c语言版本的)
1 |
|
区域赛-有趣的小游戏
运行一下程序,是一个迷宫游戏,但是金币(C)的位置是随机的,并且会随机到封闭的空间里面。那就先查壳,放到IDA里面进行分析。
分析main函数
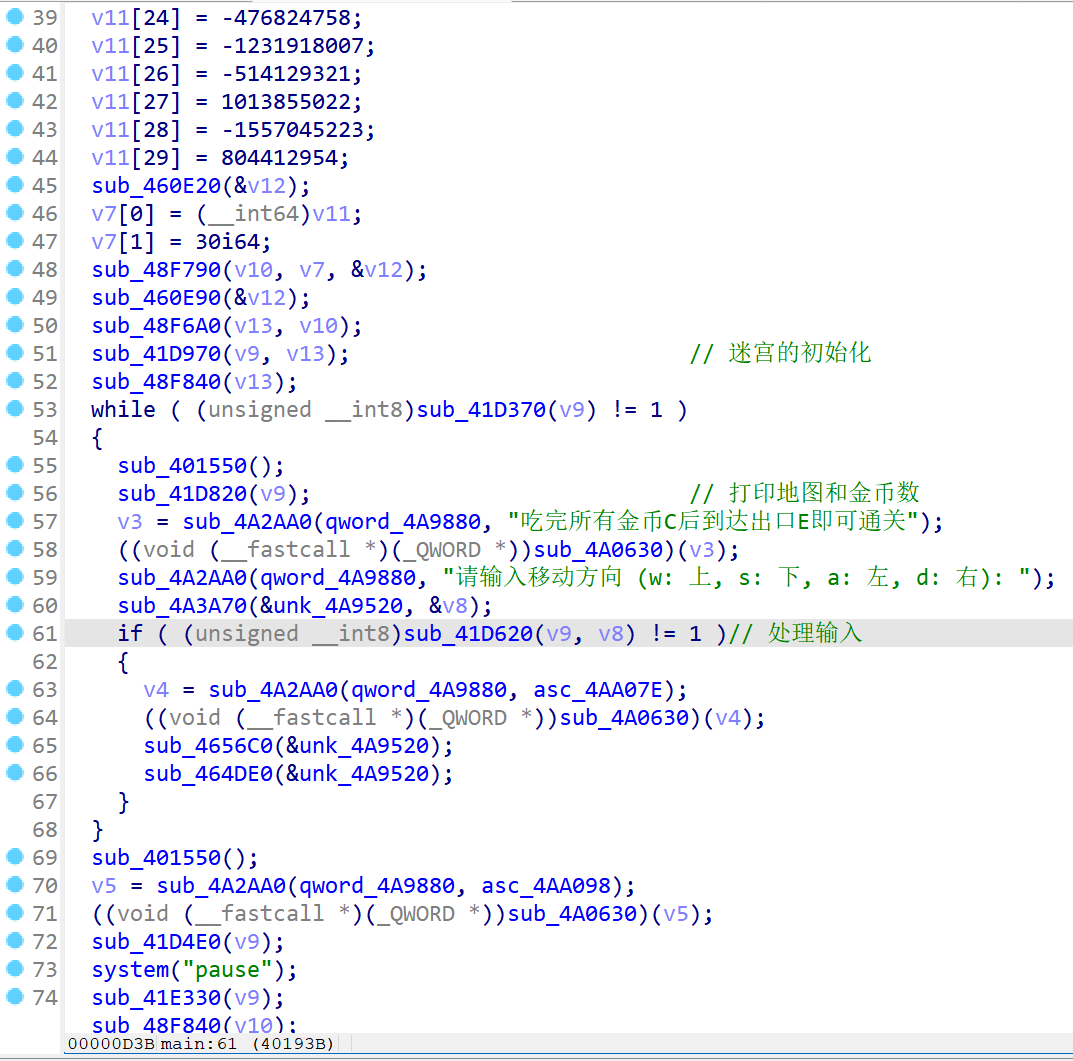
大概逻辑就是 它先把一份被整数数组保存的关卡数据解码成地图,然后进入一个循环,让用户输入 w/s/a/d 控制移动;当满足“吃完所有金币并到达出口”的通关条件后,输出成功信息并结束。
跟进sub_41D970函数看看,这个函数是迷宫的初始化
1 | _BYTE *__fastcall sub_41D970(_DWORD *a1, __int64 a2) |
我们能知道,这个程序在一开始构造一段固定的 30 个 32 位整数作为初始状态,传入 sub_41D970函数里面,这个函数就是负责初始化迷宫对象,构建固定的迷宫地图,记录玩家的初始坐标P和终点坐标E。设置总金币数是1000。
然后跟进sub_41D820函数看看它是什么作用
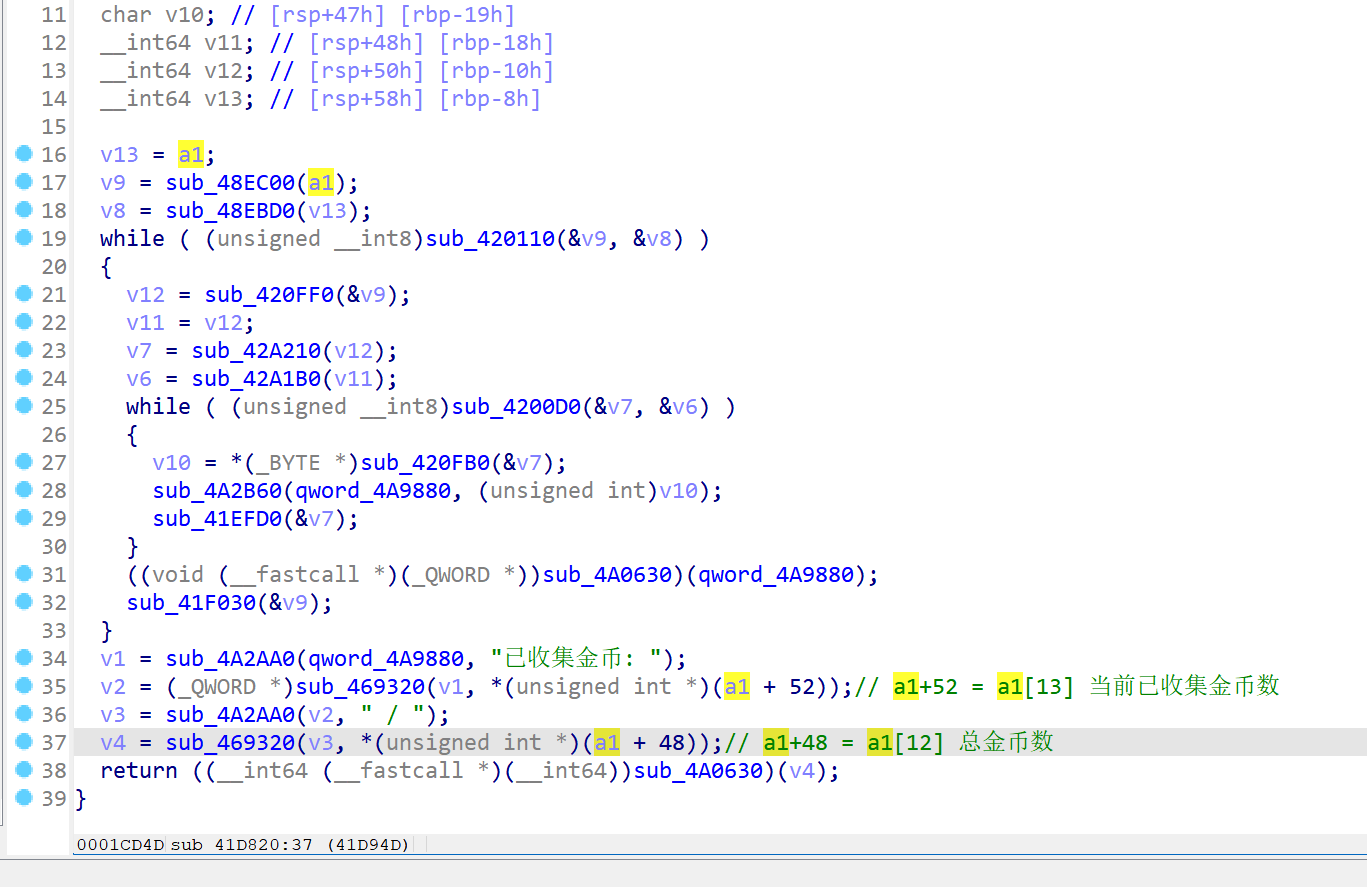
这个函数就是打印当前的地图和收集的金币数。
接下来就是一些提示,提示输入移动方向,我们输入的方向存在v8里面。
然后跟进sub_41D620函数,他就是对我们的输入进行处理的函数,看看具体干了什么。
1 | __int64 __fastcall sub_41D620(_DWORD *a1, char a2) |
继续跟进sub_41D580函数
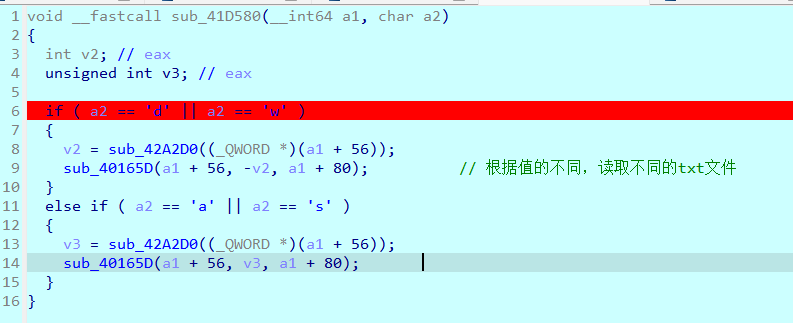
这个是根据方向的不同分别进行不同的操作,然后去调用sub_40165D函数。
跟进去看看
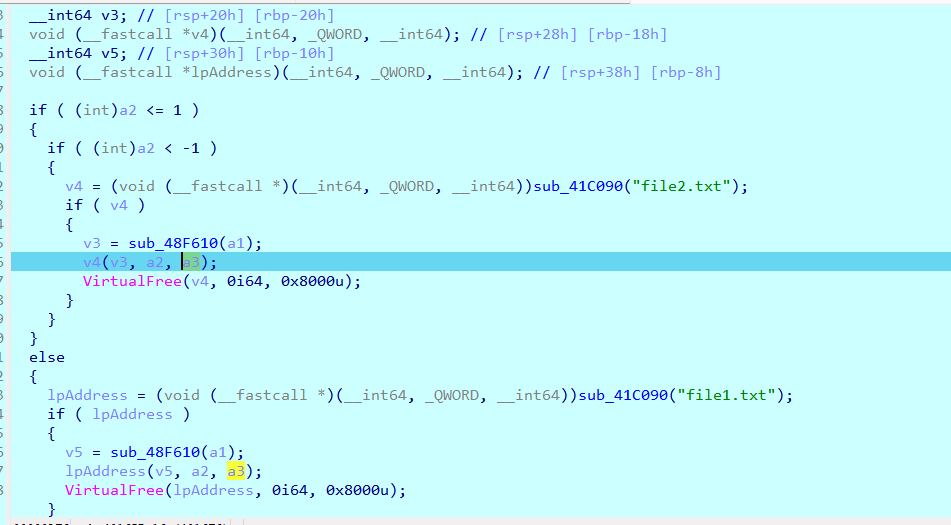
如果 a2 > 1,加载 file1.txt 中的代码,执行它
如果 a2 < -1,加载 file2.txt 中的代码,执行它
如果 -1 <= a2 <= 1,什么都不做
我们并不知道这个file文件里面被加载到程序里是什么逻辑,静态看不出来,所以要动态调试,在sub_41D580((__int64)a1, a2); 处下断点。
动调到加载file2文件的内容,双击跟进v4,然后按d,跳转地址

按U,按P,进行函数重新定义,就看到了真面目。
动调出来的XXTEA,这个是解密算法。
按位与 & > 按位异或 ^ > 按位或 |
& 优先级高于 ^
a ^ b & c 即 a ^ (b & c)

所以a1是密文,a3是key。
明文直接双击可以找到,一共是30个值
回顾这个sub_40165D函数,v4就是要进行的XXTEA解密算法,输入的a3就是key
或者等到运行到a3的时候,双击进去就能看到值
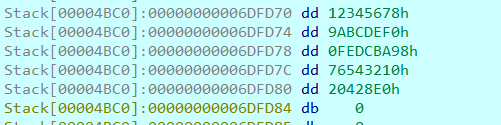
密文和key都知道,而且解密算法也知道了是标准的XXTEA,那么就可以求解了,真的可以求解了吗?
经过动调分析
当进行a/s的操作的时候,会加载了file1的内容,这个是XXTEA的加密,key还是a3,不发生改变。
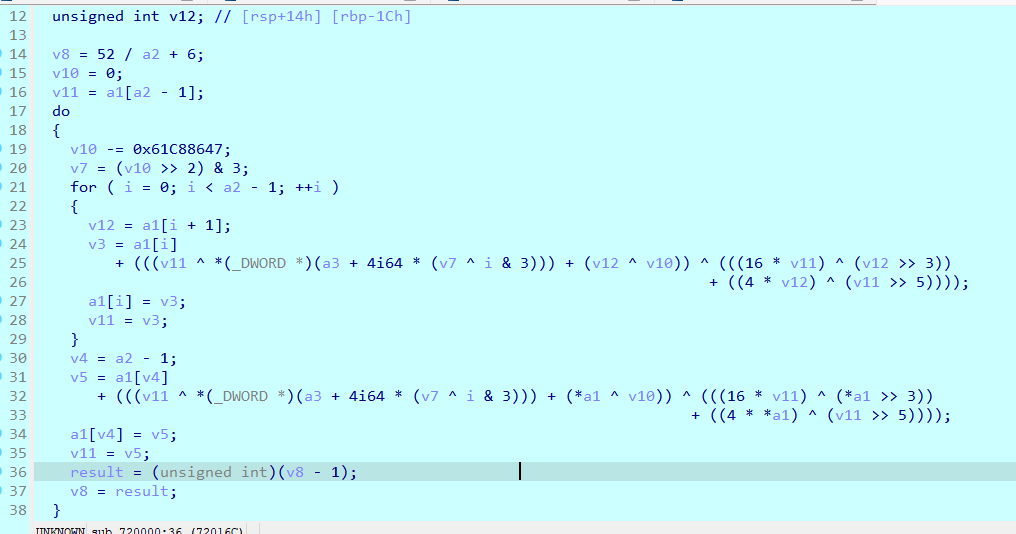
这道题的特点就在于,看着是迷宫题,需要吃完所有的金币,但是吧,每一次移动并不只是移动,而是对内部状态做XXTEA加解密。经过动调分析,我们进行w/d操作的时候,是加载了file2文件,进行了XXTEA解密。当操作a/s的时候,是动态加载了file1文件,是XXTEA加密。
并且每次吃到金币后,程序还会额外执行一次 ‘d’对应的解密操作,再刷新剩余金币的位置。因此正确的路径不再是以前经典迷宫题目求最短路径什么的,而是一串满足状态转换条件的XXTEA加解密操作序列。总解密次数是w+d+金币数,总加密次数是a+s。
那想得到flag,到底是谁大于谁呢,应该加密几次,解密几次呢?
地图是固定的,我们的初始位置和终点的位置是固定的,每次刷新的都是金币的位置。所以每次第一步都是w操作,也就是将密文进行XXTEA解密。而且我们知道的是金币数是1000,那就很明显了解密数会大于加密数。
那么不知道到底进行了几次解密才解出来flag,就可以进行爆破。
我们知道flag头是ISCC,可以进行字符匹配,写出脚本
1 |
|
相逢已是上上签
先查壳,发现程序无法识别和运行。
那就放到010里面看看。
DOS部分主要是为了兼容以前的DOS系统,DOS部分可以分为DOS MZ文件头(IMAGE_DOS_HEADER)和DOS块(DOS Stub)。
其中重要的是e_magic成员和e_lfanew成员。e_magic就是魔数,文件开头两个字节MZ(0x4D,0x5A),e_lfanew是指向 PE Header 的文件偏移地址。一般在第四排四个字节指向的地址会指向真正的 PE 头(50 45)。这两个条件满足,就是一个有效的PE文件。
DOS块的部分就是PE文件头和DOS MZ文件头中间的部分。这部分是由链接器所写入的,可以随意进行修改,并不影响程序的运行。
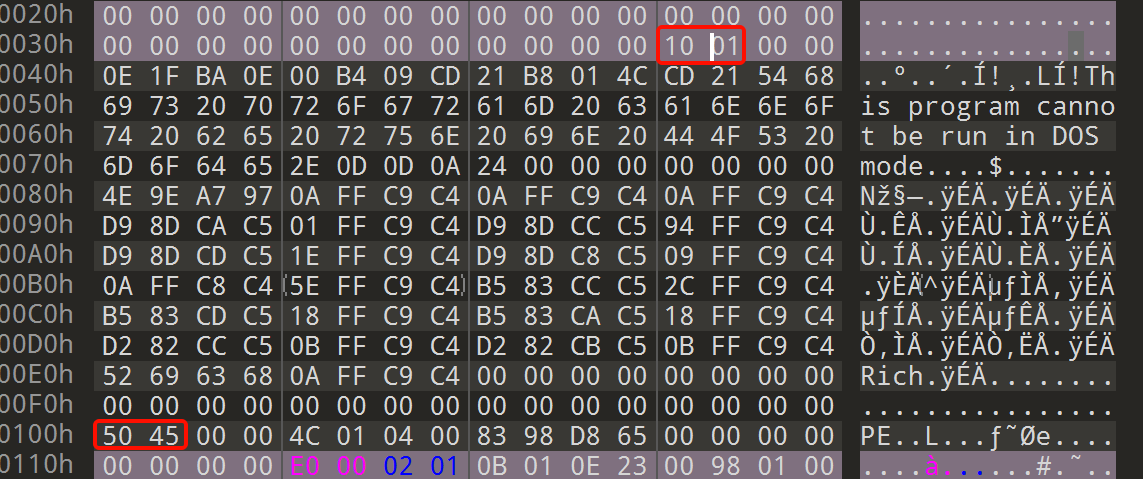
这个e_lfanew指向的偏移地址是错误的,我们能看到 50 45在100h的地方,这里 10 01 00 00 是小端序,其值是0x00000110,所以这个偏移错误的指向了0x110,而不是0x100。想要正确指向0x100,就要改成 00 01 00 00
保存后就能识别出PE文件了。
分析main函数
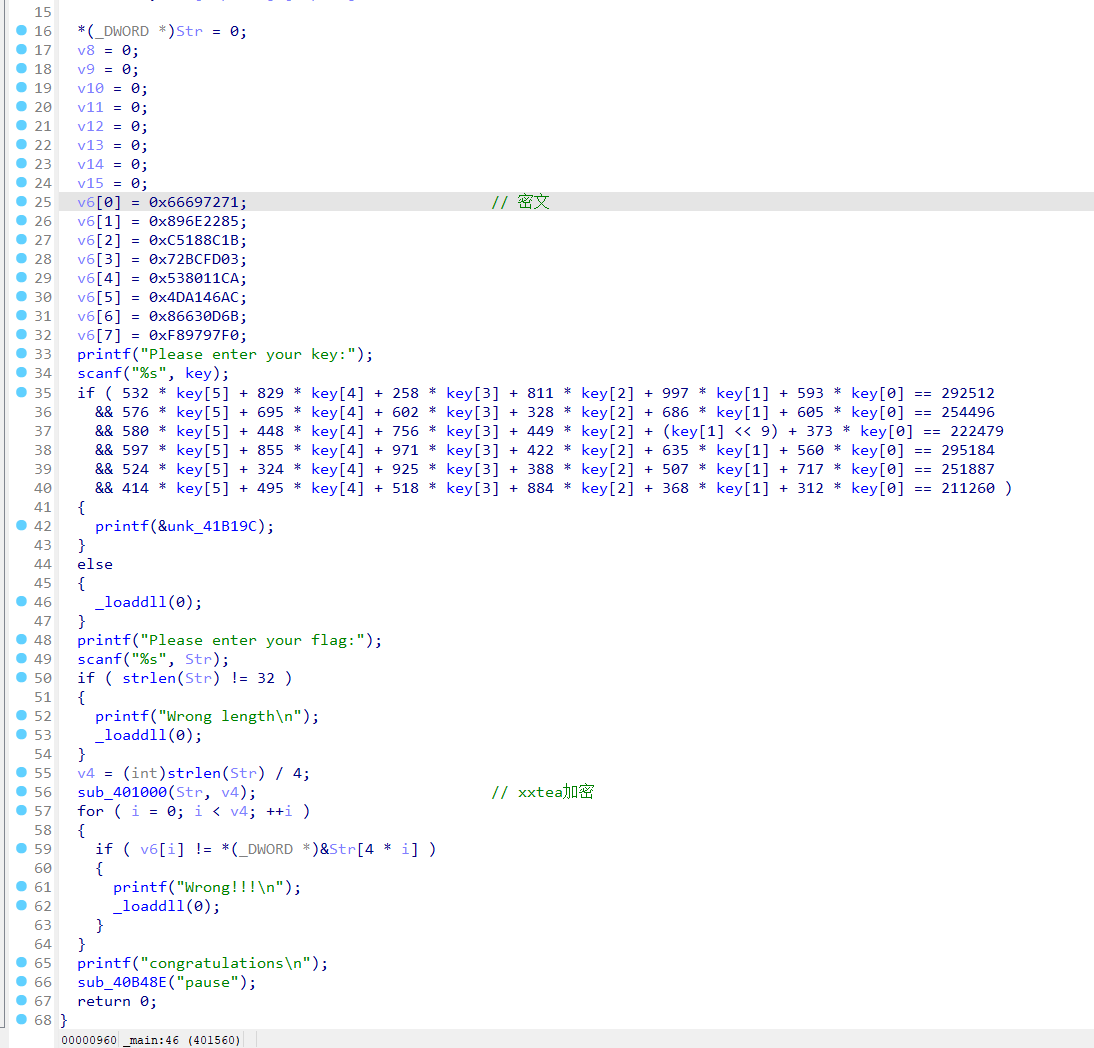
key通过z3可以约束求解
1 | from z3 import * |
xxtea加密算法
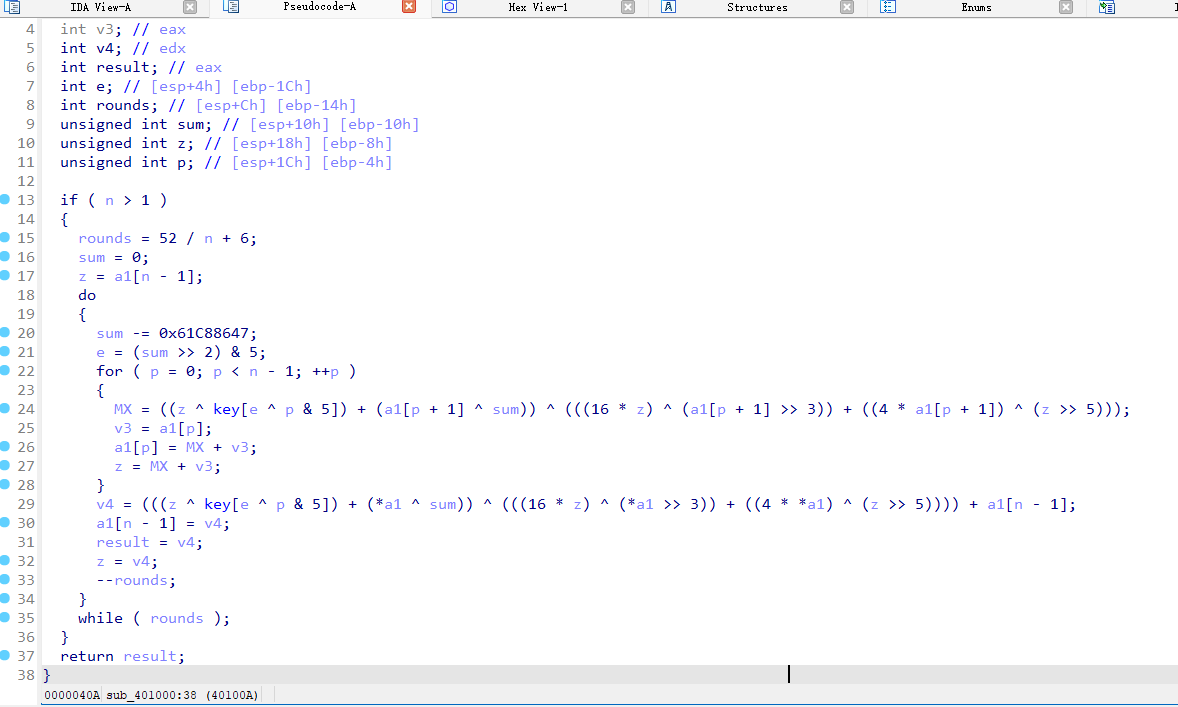
这个是标准的xxtea加密,现在已知key和密文,可以直接套脚本去解密
解密脚本如下
1 |
|


